YOLO v3는 v2와 v1처럼 뭔가 새로운 방식을 제시하기보다는 다른 사람들의 아이디어들을 차용하는 방식으로 v2의 성능을 올린 논문이다. 따라서 논문 자체도 굉장히 짧게 구성되어있다.
YOLO v3
YOLO v3는 개선 위주의 내용이다 보니 대부분의 아키텍처는 yolo v2와 동일하다. 주요 변경점은 아래와 같다.
- Feature extraction을 Darknet-19에서 Darknet-53으로 변경
- FPN과 같이 다양한 크기의 feature map을 사용해 bounding box 예측
- Class score를 예측할 때 Softmax를 사용하지 않고 개별 클래스 별로 binary cross entropy 사용
1.Bounding box
\[b_{x} = \sigma{t_{x}}+c_{x} \\ b_{y} = \sigma{t_{y}}+c_{y} \\ b_{w} = p_{w}e^{t_{w}} \\ b_{h}= p_{h}e^{t_{h}}\]기존 bouding box에 대한 예측은 ground truth box가 \(g_{*}\)일 때 \(b_{*}\)와 L2 loss를 이용해 학습을 했었는데. 컨셉을 바꿔 ground truth box의 \(\hat{t}_{*}\)를 구하고 모델의 예측인 \(t_{*}\)의 L1 loss를 이용해 학습을 진행한다.
objectness score는 이전과 같이 logistic regression을 사용한다. 가장 높은 IOU를 가지는 box가 1의 값을 가지고 만약 box의 IOU가 특정한 threshold 값보다는 높지만 가장 높은 IOU가 아닐때에는 loss에서 무시된다(특정한 threshold보다 높을 때 assign되었다고 한다). YOLO v3에서는 0.5의 threshold를 사용하고 만약 box가 assign되지 않았다면 box와 class에 대한 loss는 전파하지 않고 objectness에 대해서만 전파한다.
2.Class Prediction
YOLO v3에서는 Class prediction을 하기 위해 softmax를 사용하지 않는다. 저자는 softmax가 좋은 성능을 위해 불필요하다고 말하며 독립적으로 모든 라벨에 대해 binary cross-entropy loss를 계산한다.
3.Architecture
YOLO v3는 Darknet-19에서 Darknet-53으로 feature extraction model을 변경했다. Darknet-53은 resnet과 같은 block을 구성한다. 아래 표에서 Residual이라고 표기된 위치에서 바로 전 레이어와 3번째 전 레이어를 더한다.
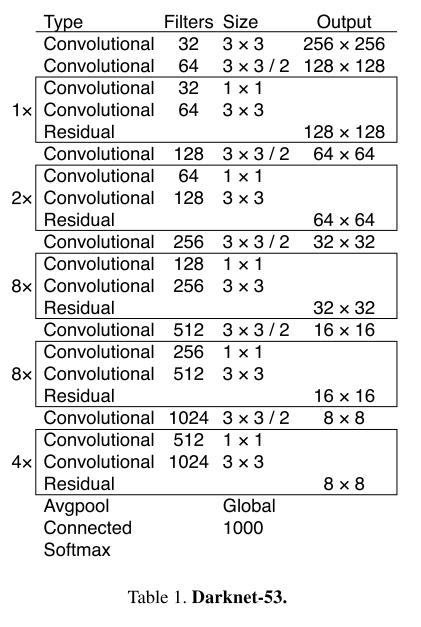
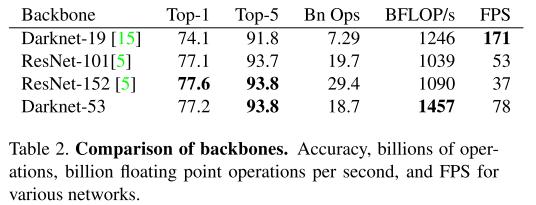
또한, 아래의 성능표를 통해 Darknet-53은 resnet-101보다 정확도와 속도면에서 우수한 성능을 보여주고 ResNet-152와는 약간의 성능차가 나는 반면 속도는 2개에 가까운 것을 보여준다.
YOLO v3는 FPN(Feature pyramid networks for object detection)과 같이 다양한 크기의 feature map을 통해 bounding box, objectness, class prediction을 수행한다. 가장 작은 feature map부터 예측과 upsampling을 반복해 약간 UNet과 같이 보이기도 한다.
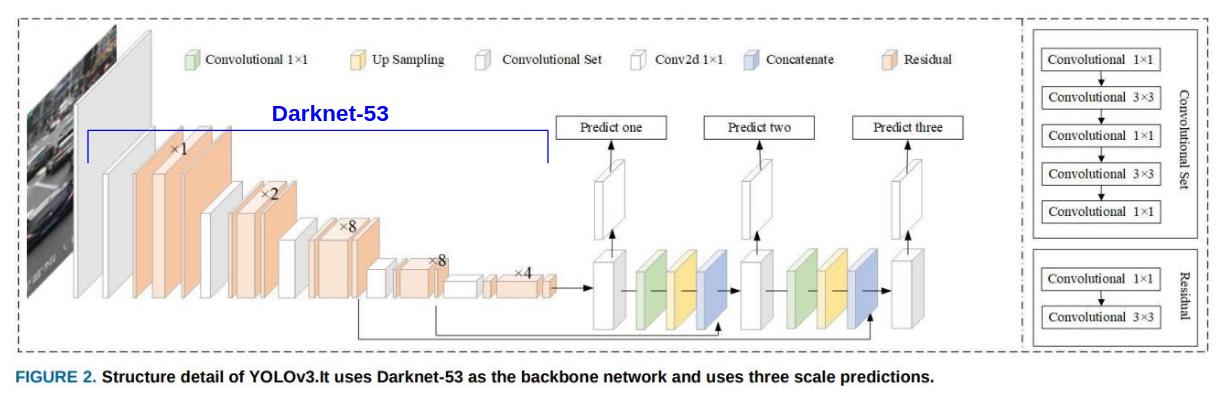
그림출처 : Mini-YOLOv3: Real-Time Object Detector for Embedded Applications
Things We Tried That Didn’t Work
아래는 yolo에 적용했을 때 효과가 없었던 기법들이다.
- anchor box의 x,y의 offset을 너비나 높이의 비율로 예측하는 방식은 오히려 모델 학습을 불안정하게 했다.
- anchor box의 x,y의 offset을 logistic activation대신 linear activation을 사용해봤으나 mAP의 성능이 낮아졌다.
- RetinaNet의 focal loss를 적용해봤지만 오히려 mAP가 낮아졌다. 이부분은 아마 objectness prediction이 해당 역할을 이미 해주기 있는 것으로 예상한다.
- Faster R-CNN에서는 0.3~0.7 IOU의 loss는 무시, 0.7이상은 positive, 0.3이하는 negative로 sample을 했었고 yolo에서 이와 유사한 sampling 전략을 사용했으나 결과가 좋아지진 않았다.
Result
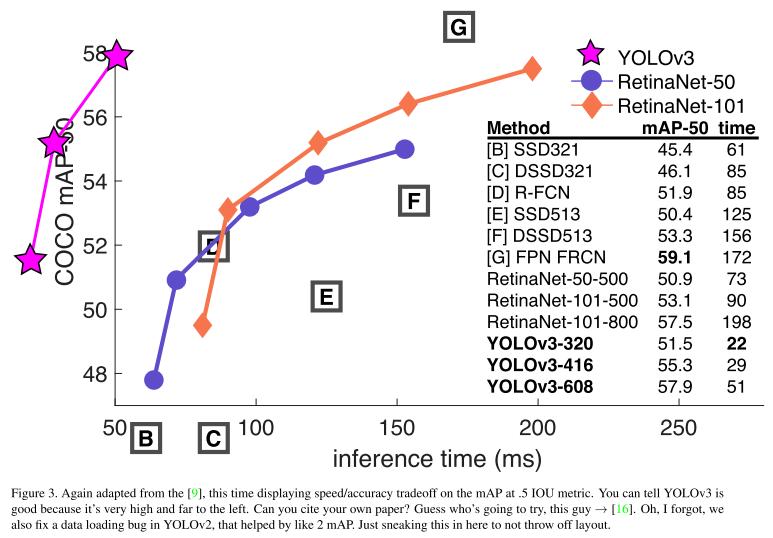
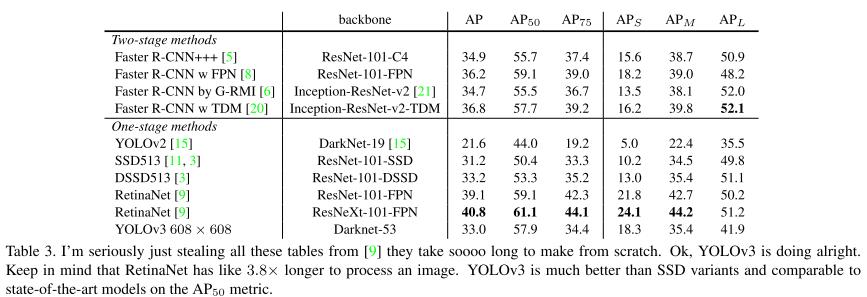
위의 표에서 YOLOv3가 생각보다 안좋다는 생각을 할 수도 있다. 하지만 실제 사람도 0.3~0.5의 IOU를 구분하는 것을 어려워하는 상황에 이는 문제가 되지 않고 0.5 IOU 기준으로는 충분한 성능을 보인다. 반면 속도는 거의 2배다.
yolo v3는 아래와 같이 평소에 괴짜로 보이던 모습과는 다른, 저자가 가진 연구자로써의 책임과 그에 대한 고민을 언급하며 끝을 맺는다.

Reference
[1] J. Redmon, A. Farhadi. YOLOv3: An Incremental Improvement. In 2018
Comments