2015년 나온 YOLO는 Faster R-CNN보다 무려 6배 가량의 빠른 속도를 보여준다. YOLO는 이름을 보면 알 수 있듯이 이후에 나오는 SSD와 함께 1-stage의 대표적인 논문이다. 비록 정확도는 낮지만 이 부분은 이후 v2, v3로 갈수록 보완이 된다.
YOLO Arichtecture


위의 그림은 YOLO의 대략적인 방법과 구조를 나타낸다. 먼저 이미지를 \(S \times S\) grid로 나누고 B개의 box정보와 confidence score, 그리고 C개의 class 확률을 예측한다. 최종 confidence는 박스가 얼마나 오브젝트를 포함하고 있는지, 그리고 박스의 예측이 얼마나 정확한지에 대한 정보이다. 첫 번째 fc layer와 두 번째 fc layer사이에는 overfitting을 피하기 위해 50% dropout이 적용 되어 있다.
논문에서는 S=7,B=2, C=20 (PASCAL VOC 2007의 class수)로 설정되어 최종 output의 shape은 7x7x30(2*5+20)이 된다.
해당 논문의 목적 식은 아래와 같다.
\[\lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbf{1}_{ij}^{obj} \left[(x_{i}-\hat{x}_{i})^{2} + (y_{i}-\hat{y}_{i})^{2} \right] + \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbf{1}_{ij}^{obj} \left[(\sqrt{w_{i}}-\sqrt{\hat{w}_{i}})^{2} + (\sqrt{h_{i}}-\sqrt{\hat{h}_{i}})^{2} \right] + \\ \sum_{i=0}^{S^2}\sum_{j=0}^{B}\mathbf{1}_{ij}^{obj}(C_{i}-\hat{C_i})^{2}+\lambda_{noobj}\sum_{i=0}^{S^{2}}\sum_{j=0}^{B}\mathbf{1}_{ij}^{noobj}(C_{i}-\hat{C}_{i})^{2}+\sum_{i=0}^{S^2}\mathbf{1}_{i}^{obj}\sum_{c \in classes}(p_{i}(c)-\hat{p}_{i}(c))^{2}\]\(\lambda\)는 목적식의 가중치를 주기위한 파라미터이다. 논문에서는 간단하게 SSE(Sum Squared Error)를 사용하였는데 bounding box에 가중치를 더 크게 주지 않으면 confidence score가 초기에 0으로 수렴해버린다고 한다. 또한, 물체를 포함하지 않는 bounding box가 더 많기 때문에 \(\lambda_{noobj}\)는 적은 가중치를 갖는다. 본 논문에서는 \(\lambda_{coord} = 5\), \(\lambda_{noobj}=0.5\)로 설정되었다.
위 식에서 \(\mathbf{1}_{ij}^{obj}\)와 \(\mathbf{1}_{ij}^{noobj}\)는 각각 물체일 때, 물체가 아닐때 1, 그외에는 0이다. 즉, object가 발생했을 때, class 확률에 대해 loss를 계산한다. 이 부분이 논문에는 \(Pr(Class_{i} \mid Object)\)로 표현된다. 그리고 논문에서는 해당 그리드 셀에서 가장 IOU가 높은 bounding box에 대해 “responsible”하다고 판단하고 해당 box에 대해서만 loss를 계산한다. bounding box의 w와 h는 root를 사용하는데 바운딩 박스의 크기의 편차를 줄이기 위해 root를 썼다고 한다.
train에 대한 정보는 아래와 같다.
- Batch size : 64
- Momentum, Decay : 0.9, 0.0005
- Epoch : 135 epoch for VOC 2007 and VOC 2012
- Learning rate
- First epoch : \(10^{-3}\) to \(10^{-2}\)
- 75 epoch after that : \(10^{-2}\)
- 30 epoch after that : \(10^{-3}\)
- 30 epoch after that : \(10^{-4}\)
- Data augmentation
- HSV 색상 공간에서 최대 1.5까지 exposure, saturation 랜덤 조절
- random scaling
- 20%의 translation
Inference
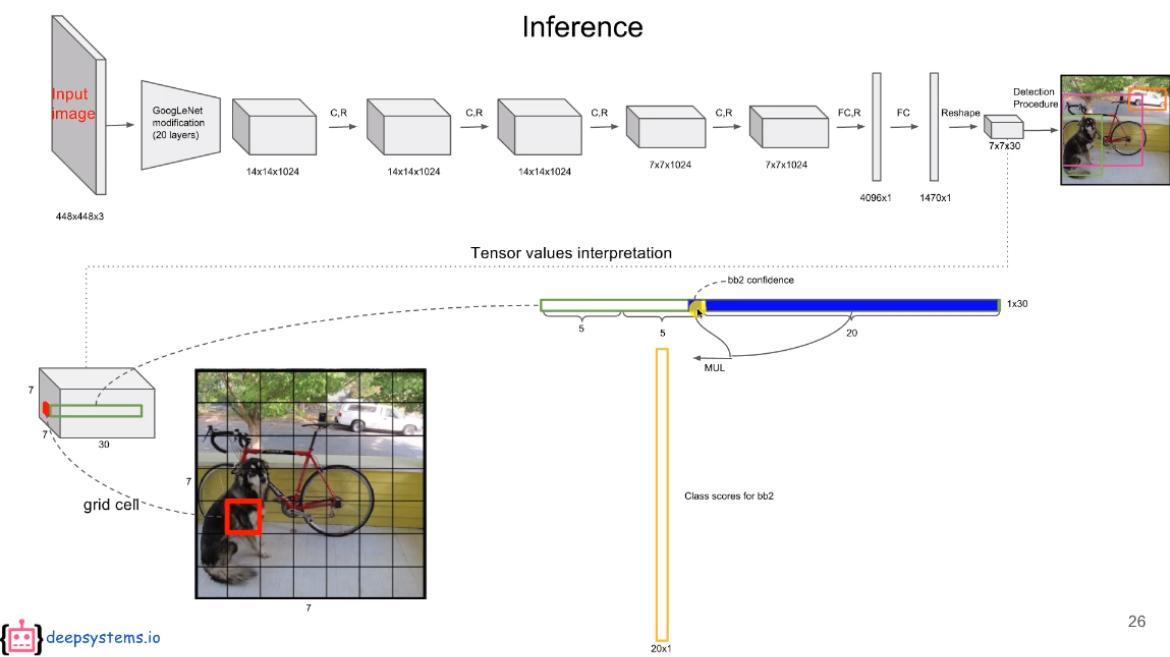
inference시에는 제일 처음 벡터를 만든다. 각 gird cell에는 위와 같이 1x30크기내에 20개의 class, 2개의 confidence 2개의 1x4 크기의 bounding box 정보가 있다. 이 정보들 중 벡터는 20개의 class와 2개의 confidnece score를 곱해 만들어 진다. 따라서 한 셀당 20개의 (confidence x class) score와 4개의 bounding box정보를 가지는 1x24 크기의 벡터가 총 2개 만들어진다.
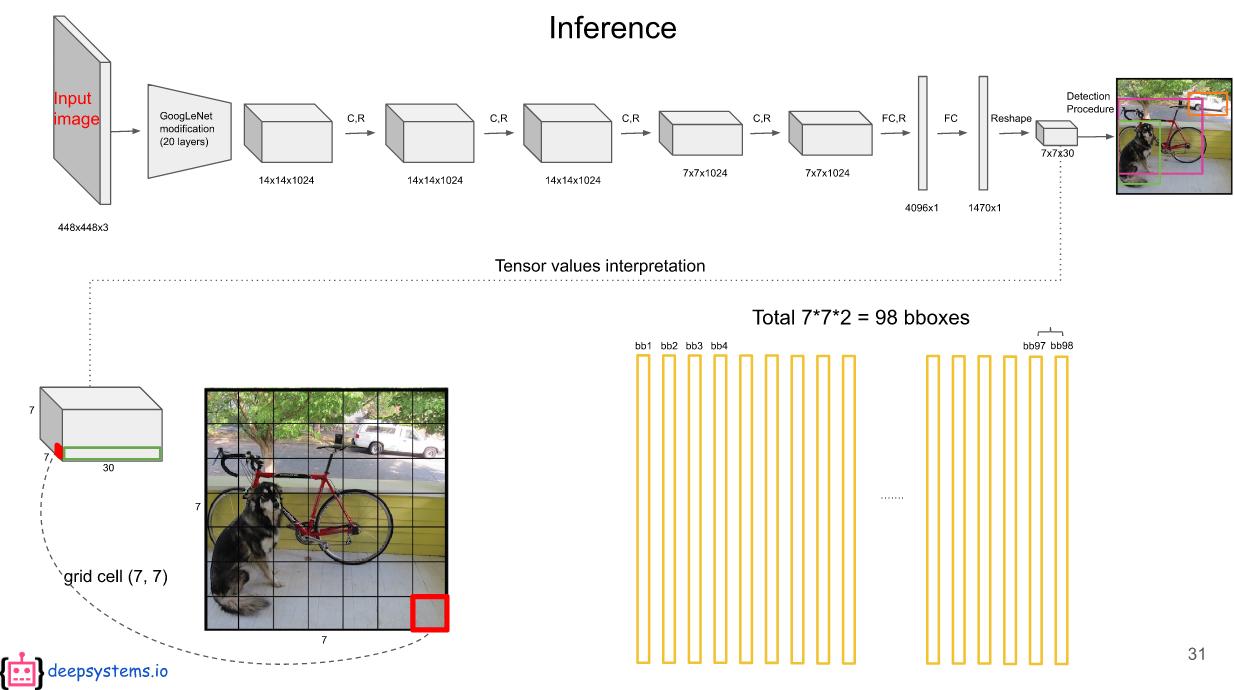
논문에서는 S의 크기가 7이므로 \(7 x 7 x 2 = 98\)개의 벡터가 생성된다.
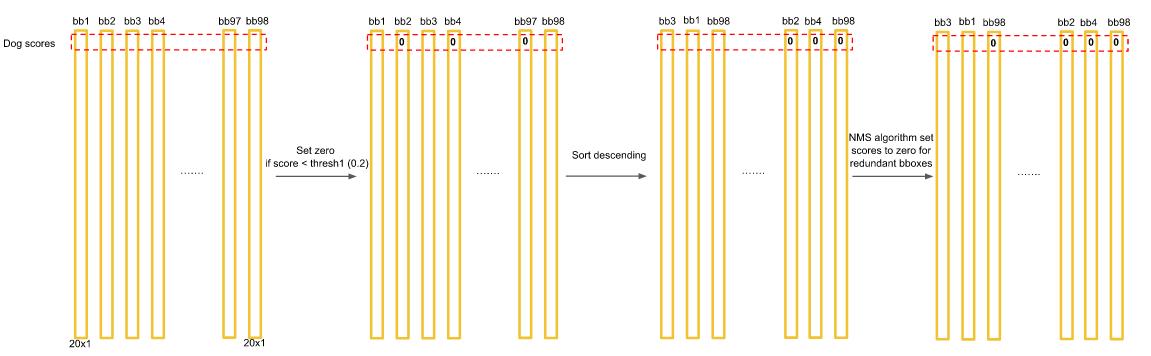
벡터가 생성된 이후에는 하나의 클래스에 대해 내림차순으로 sorting을 하고 thresold(0.2)이하의 값을 가지는 score는 0으로 취급된다. 그리고 NMS 과정을 거쳐 최종 bounding box를 그리는데 이에 대해서는 추가적으로 설명한다.


강아지에 대해 점수별로 sorting을 했기에 맨처음 벡터는 위와 같이 가장 높은 정확도를 보여준다. 하지만 두 번째부터는 첫 번째와 동일한 강아지를 예측했을 수도 있고 다른 위치의 강아지를 예측했을 수도 있다. 이를 위해 NMS를 적용한다.
두 번째 box(bb20)은 첫 번째 box(bb47)와 0.5이상의 IOU를 가지기 때문에 0이 된다. 세 번째(bb15)와 네 번째(bb7)는 첫 번째(bb47)와 0.5이하의 IOU를 갖기 때문에 첫 번째 기준으로는 지워지지 않지만 세 번째와 네 번째는 서로 0.5이상의 IOU를 가져 더 높은 스코어인 세 번째만 최종적으로 지워지지 않고 네 번째는 지워진다.

이렇게 부분적으로 0이 된 각각의 벡터에 대해 가장 높은 index가 0 이상일 경우 최종 bounding box가 된다.
Result


위 결과에서 비록 정확도는 Faster R-CNN에 비해 떨어지지만 FPS는 상당히 높음을 알 수 있다.
Reference
[1] J. Redmon, S. Divvala, R. Girshick, and A. Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016
Comments