YOLO 9000이라는 제목으로 나온 이 논문은 YOLO의 후속작으로써 YOLO v2라고도 불린다. 괴짜 답게 소제목을 Better, Faster, Stronger로 구성했으며 빠른 속도와 무려 9000 종류의 물체를 구분하는 등 놀라운 성능을 보인다.
Better
YOLO는 분명 빠른 속도를 가지고 있었지만 Fast R-CNN과 같은 region proposal model에 비해 낮은 recall을 갖는다. 저자는 다음과 같은 방법으로 recall과 localization 성능을 올리면서 classification 정확도를 유지했다.
1.Batch Normalization
Batch Normalization은 Gradient vanish/ exploding가 internal covariance shift에 의해 일어난다는 가정(“ How Does Batch Normalization Help Optimization?“에서는 BN을 써도 internal covariance shift가 일어나기 때문에 직접적인 원인은 아니고 gradient를 좀더 reliable하게 만들어 준다고 한다.)하에 batch 단위로 각 feature들의 평균과 표준편차를 이용해 Normalization하는 방법이다. YOLO 역시 이 방법을 채택하고 dropout을 제거했다. 이로 인해 2%의 mAP를 상승시켰다.
2.High Resolution Classifier
AlexNet에서 시작된 대부분의 분류 모델들은 256 x 256 보다 작은 이미지에서 모델을 훈련했다. YOLO로 역시 pre-trained된 모델을 사용했으며 해당 모델은 224 x 224 크기의 이미지에 대해 훈련되었다. 이로인해 448 x 448 크기의 이미지에 대해 적절한 학습이 되어 있지 않았다. 따라서 YOLO v2는 448 x 448의 크기로 ImageNet에서 약 10 epoch 동안 fine tuning을 진행한다. fine tuning에 의해 약 4%의 mAP를 상승시켰다.
3.Convolutional With Anchor Boxes
SSD, Faster R-CNN과 달리 YOLO는 가이드라인 없이 bounding box의 정보를 예측 했었다. YOLO v2에서는 다른 모델과 같이 Anchor box를 도입해 가이드라인을 제공한다. 또한, 모델 구조에서 fc layer들을 모두 conv layer로 변경했다. 그리고 마지막 feature map의 경우 큰 object 들은 이미지 중심에 위치하는 경우가 많아 홀수의 크기를 갖는게 좋다고 한다. 이로인해 448 x 448 입력을 416 x 416으로 변경하였다.
anchor box없이 사용했을 때 69.5mAP와 81%의 recall을 얻었고 anchor box를 도입 했을 때 69.2 mAP와 88% recall을 얻었다. 비록 mAP는 낮아졌지만 당초의 목적과 같이 recall의 상승을 얻을 수 있었다.
4.Dimension Clusters
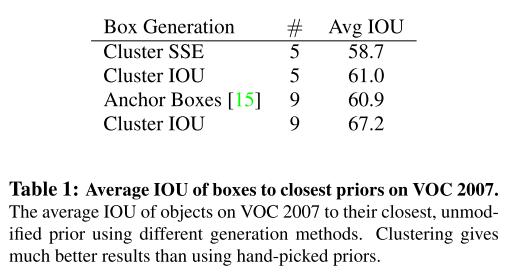
이전의 논문들은 Anchor box의 크기나 종횡비를 사람이 직접 정했다. YOLO v2에서는 단순히 종횡비나 크기를 정해주는 것보다 더 최적의 box가 있을 것이라 판단했고 이를 찾게 된다면 더 쉽게 학습이 이루어 질 것이라고 했다. 논문에서는 training dataset에서 k-mean clustering을 적용해 최적의 anchor box를 찾았다. 일반적인 k-mean clustring은 유클리디안 거리를 사용하지만 bounding box에 대해서는 정확하지 않다. 따라서 거리에 대한 식을 IOU에 대한 식으로 변경했다.
\[d(box,centroid) = 1-IOU(box,centroid)\]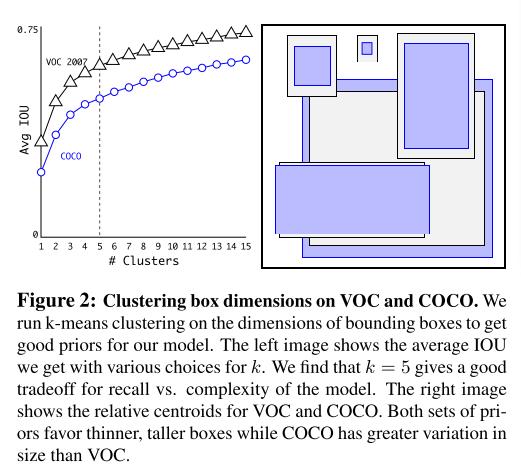
k가 5일 때 모델의 복잡성과 높은 recall사이의 적절한 tradeoff가 일어난다고 한다.
5. Direct location prediction
이전의 anchor box들의 loss에는 제한이 없었다. 이로 인해 중심 셀에서 상당히 떨어진 위치에 bounding box를 예측하는 일이 발생하기도 한다. YOLO v2에는 이에대한 제약사항을 추가하기 위해 sigmoid를 적용한다.
\[b_{x} = \sigma(t_{x}) + c_{x} \\ b_{y} = \sigma(t_{y}) + c_{y} \\ b_{w} = p_{w}e^{t_{w}} \\ b_{h} = p_{h}e^{t_{h}} \\ Pr(object) * IOU(b,object) = \sigma(t_{o})\]여기서 \(t_{xx}\)들은 network의 output을 나타낸다. 이로 인해 5%의 성능을 향상 시킬 수 있었다고 한다.
6.Find-Grained Features
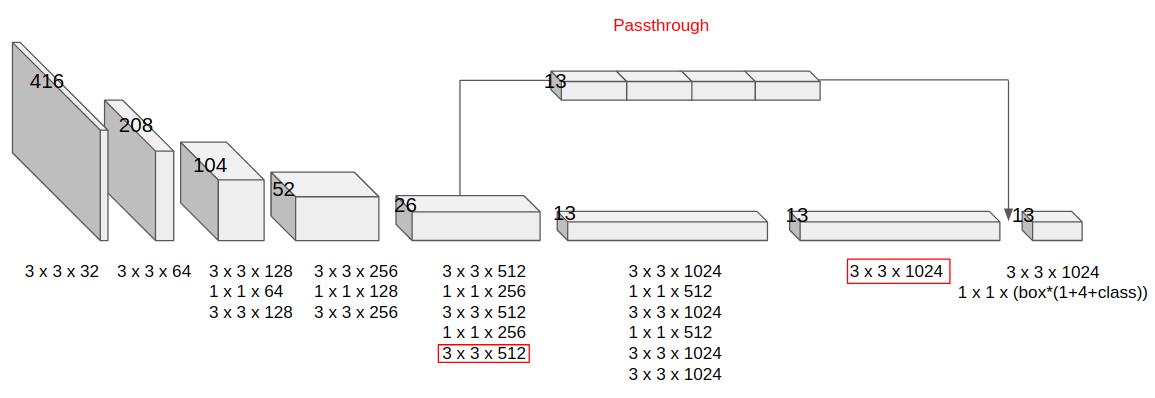
YOLO v2의 최종 output은 13 x 13 grid이다. 이전 버전에 대해 작은 물체에 대한 성능이 뒤떨어진다라는 평이 있었다. 그래서 상위에 26 x 26 크기를 가지는 feature을 4등분 하여 마지막 convolution 전에 합쳐준다(Passthrough layer). 이로인해 1%의 성능을 향상 시킬 수 있었는데 데이터셋의 대부분이 어느정도의 크기를 갖는 점을 생각하면 꽤 많이 오른것 같다.
7.Multi-Scale Training
YOLO v2는 이전 버전과 달리 fully convolutional network이다. 저자는 이 강점을 살려서 다양한 scale에 적응한 network를 만들었다. 저자가 제시하는 방법은 다음과 같다. input image의 size를 항상 고정하지 않고 매 10 batch 단위로 다양한 image size를 갖는다. 이때 이미지 사이즈는 32의 배수로 설정하며 최소 320부터 608의 범위를 갖는다.
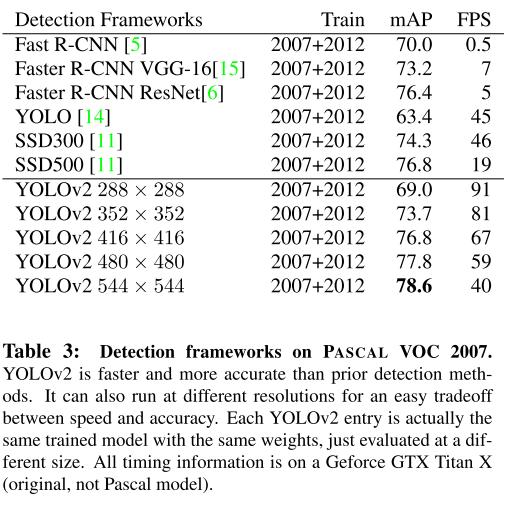
아래는 PSACAL VOC 2007 dataset에서 각 이미지 사이즈별 정확도와 속도를 보여준다.
아래 표는 YOLO v1과 각 방법들을 적용했을 때의 정확도를 보여준다.
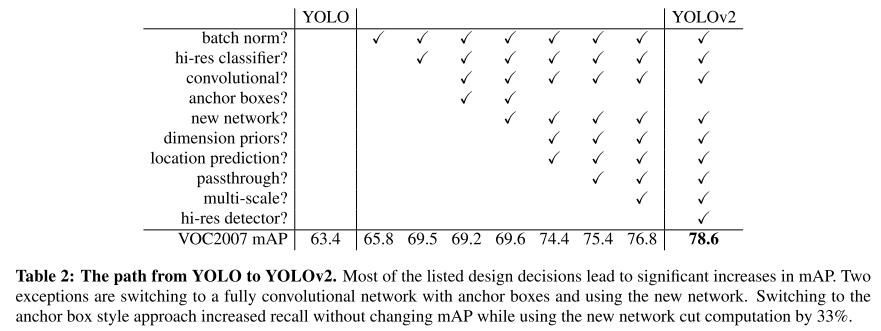
Fater
VGG16은 높은 정확도로 많은 모델에서 사용된다. 하지만 224 x 224 크기의 이미지를 입력으로 받았을 때 30.69 billion 만큼의 부동 연산이 요구된다. 이전의 YOLO는 VGG16 대신 8.52 billion 연산을 요구하는 GoogleNet을 사용했지만 VGG를 채택했을 때 90.9%의 정확도를 가진 반면 GoogleNet을 채택했을 때 88.0%로 정확도가 낮아졌었다.
따라서 논문의 저자는 VGG와 유사하지만 NIN 논문의 1 x 1 conv layer를 적극 활용하고 훈련의 안정화, 수렴의 속도 향상, 모델의 정규화에 효과적이라는 BatchNormailization을 사용하는 모델을 설계한다. 이 모델의 이름은 Darknet-19라고 지었으며 5.58 billion 연산 요구량과 이미지넷에서 top-1 72.9%, top-5 91.2%의 정확도를 획득했다. 아래는 입력 224 x 224 일때의 DarkNet layer들의 커널 정보, output shape을 보여준다.
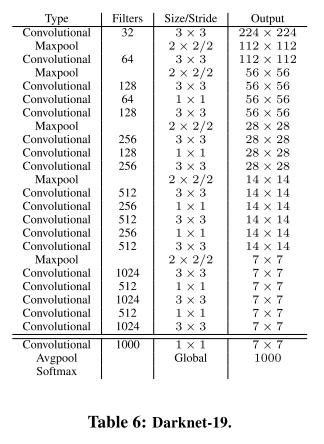
Training for classification
train은 2단계로 나뉜다.
- 공통사항
- Dataset : ImageNet
- Optimizer : Stochastic gradient descent(momentum = 0.9, weight decay = 0.0005)
- Data augmentation: random crop,rotations,hue,saturation,exposure shifts
- Initial training
- Input image shape : 224 x 224
- Epochs : 160
- learning rate : 0.1 and Polynomial rate decay with a power of 4
- fine tuning
- Input image shape : 448 x 448
- Epochs : 10
- learning rate : 0.001
fine tuning 기준으로 top-1은 76.5%, top-5는 93.3%의 정확도를 획득했다.
Training for Detection
Detection을 할 때는 마지막 convolution layer를 제거하고 3개의 3 x 3 x 1024 conv layer과 1 x 1 x (B x (class+1+4)) conv layer를 추가한다. 또한 마지막 3 x 3 x 512 conv layer에 의한 passthrough layer를 마지막에서 2번째 3 x 3 x 1024 layer의 output과 concate 한다(6. Find-Grained Features의 그림 참고).
다른 training 환경은 아래와 같다.
- Epochs : 160
- Learning rate : 0.001, 이후 60 epoch 와 90 epoch에서 1/10
- Optimizer는 classification과 동일
- Data augmentation : YOLO, SSD에서 사용한 것과 random crops, color shifting
Stronger
YOLO v2는 2개의 Data를 섞어 train 하는 방법을 제시한다. Classification Data와 Detection Data를 섞어서 쓰는 경우 Detection의 backpropagation은 그대로 진행하고 Classification일 경우 Classification에 대한 backpropation만 진행한다.
여기서 문제가 되는 것은 label인데 논문에서 예로 든 것은 COCO와 ImageNet이다. COCO의 경우 “dog”와 같은 상위 개념의 label을 제공하며 ImageNet의 경우 “노퍽 테리어”, “요크셔 테리어” 등의 하위 개념의 label을 제공한다. 이를 위해 WordNet이라는 directed graph구조의 language Database를 사용하고 만약 해당 단어가 여러개의 부모를 가지는 경우 루트 노드까지 짧은 경로를 선택한다.
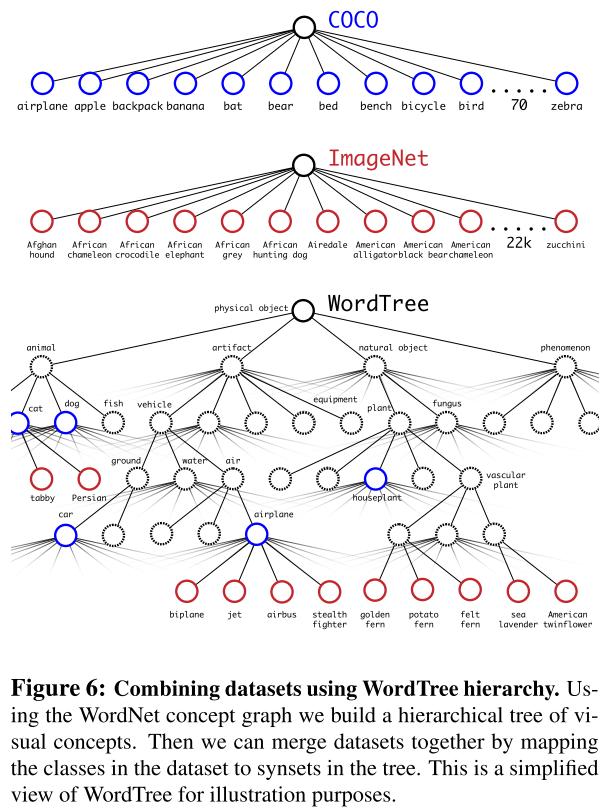
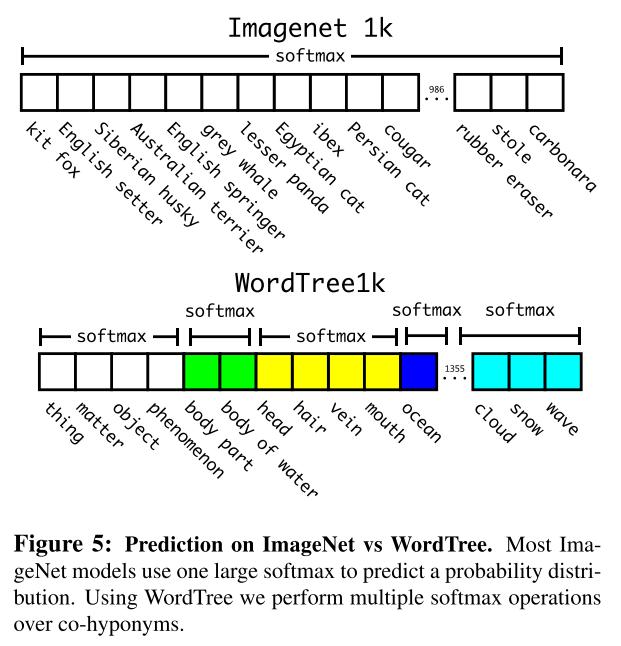
이 과정에서 “cannine(강아지와 늑대같은 개과동물)”과 같이 실제 label에는 없는 단어도 추가되어 COCO의 200개 라벨과 ImageNet의 1000개 라벨 숫자를 합친 것 보다 많은 1369개의 label이 생겼다. class에 대해서는 위의 2번째 그림과 같이 동일한 상위를 가지는 class끼리 softmax 연산을 하고 모든 label의 공통적인 루트 노드는 physical object로 object를 포함한다고 판단되면 \(Pr(physical object) =1\)이다. 하위 노드가 존재하더라도 계산은 실제 label 기준으로만 계산하며 예시로 “노퍽 테리어”에 대한 확률은 아래와 같이 계산된다.
\[Pr(Norfolk \ terrier) = Pr(Norfolk \ terrier \mid terrier) \times \\ Pr(terrier \mid hunting dog) \times ... \times \\ Pr(mammal \mid animal) \times Pr(animal|physical object)\]Darknet-19 기준으로 top-1은 71.9%, top-5는 90.4%의 정확도를 획득했다. 이로인한 이점은 처음 본 강아지 품종에 대해 정확도가 낮아지지만 여전히 “dog”에 대한 확률은 높게 나온다는 것이다. 또한, 루트 노드인 “physical object”가 값을 가질 때 bounding box의 예측이 가능하다.
YOLO 9000은 이 방식을 사용해 9000개의 class를 학습한다. Full ImageNet dataset은 몇 만개의 class를 가지고 있는데 이 중 top 9000을 선택했다. 그리고 ImageNet에 비해 COCO의 양이 너무 적어 oversampling을 해 4:1 비율을 맞췄다. 그리고 anchor box는 output size의 제한으로 인해 5개 대신 3개로 사용했다. classification image에 대해서는 class에 대해 가장 높은 probability를 가지는 box에 대해서만 class에 대한 backpropagation을 진행했다. 또한, detection image 이미지에서는 ground truth와 0.3 이상의 IOU를 가지는 box에 대해 loss를 backpropagation했다.

YOLO9000은 training 되지 않은 156 개의 객체 클래스에서 16.0mAP, training된 label에 대해서는 전체적으로 19.7mAP의 성능을 보였다. 이 수치는 DPM보다 높은 수치를 보여주며 완전히 다른 데이터세트에서 train 되었다는 차별점이 있다.
위의 결과는 YOLO 9000의 Worst와 Best class를 보여주는데 COCO에서 나오는 사람, 의류 등에 관련된 정보들은 bounding box에 대한 label이 없어서 성능이 낮은 것으로 판단하고 있다. 또한, 두개의 데이터세트에서 공통적으로 나오는 동물에 관해서는 높은 성능을 보여준다.
Reference
[1] J. Redmon, A. Farhadi. YOLO9000:Better, Faster, Stronger. In CVPR, 2017
Comments