Faster R-CNN은 이전의 Fast R-CNN의 성능을 개선했음에도 불구하고 7 FPS라는 속도를 보여준다. 물론 비약적인 발전이었지만 여전히 실시간에는 적합하지 않았다. 또한, 이후 발표된 YOLO의 경우 실시간에 적합한 속도를 보여주지만 그만큼 정확도가 낮아졌다.
본 논문에서는 후보 영역 생성과 resampling 과정을 제거하고 VOC2007 데이터 세트에서 74.3% mAP, 59 FPS라는 높은 정확도와 빠른 성능을 획득하였다.
SSD Arichtecture
어떻게 resampling 과정을 제거 하면서 정확도를 높일 수 있었을까?
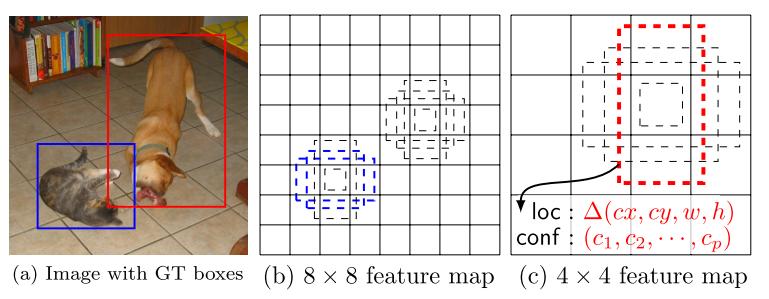
SSD의 Region proposal 전략은 위 그림과 같다. Faster R-CNN의 경우 각 영역이 object인지 판단하고 해당 영역을 ROI pooling을 통해 Fc layer로 넘겨주는 방식이었다. SSD는 YOLO와 같이 One Stage 전략을 사용하며 Conv Net feature들을 pyramid 구조로 이용한 방식이다.
pyramid 구조의 이점을 설명하자면, 8 x 8 크기의 feature map (b)에서는 고양이 크기에 대해 예측을 진행하였다면 4x4 크기의 feature map (c)의 경우 (B)보다 약 2배 크기의 box를 예측한다. Faster R-CNN과 같이 default box(Anchor box)를 사용해 box의 가이드라인을 제시해주는 점은 동일하지만 이미지 내의 오브젝트 크기에 따라 box가 예측해야 하는 범위가 큰 폭으로 달라지지 않는다는 강점이 생긴다.

위 사진은 SSD의 구조를 나타낸다. 사진을 기준으로 총 6군데(Conv4_3, Conv7,Conv8_2,Conv9_2,Conv10_2,Conv11_2)에서 추가적으로 3 x 3 x (box_num x (classes(label+1) + 4(bounding box info))) shape의 Convolution 연산을 통해 각 default box 별 class와 4개의 bounding box 정보를 예측한다.
네트워크 구조에 대해 조금더 설명하자면 Conv5_3 layer 까지는 VGG-16의 구조를 그대로 가져오고 본래 마지막 max pooling이 있어야 할 자리부터 Conv6이 시작된다. 그림에서는 Fc layer의 자리를 대신해서 위와 같이 (FC)로 표현되어 있다. Conv6 부터 Convolution 필터에 대한 정보는 아래와 같다.
| Name | filter shape |
|---|---|
| Conv 6 | 3 x 3 x 1024 / padding = 1 |
| Conv 7 | 1 x 1 x 1024 |
| Conv 8_1 | 1 x 1 x 256 |
| Conv 8_2 | 3 x 3 x 512 / padding = 1, stride = 2 |
| Conv 9_1 | 1 x 1 x 128 |
| Conv 9_2 | 3 x 3 x 256 / padding = 1, stride = 2 |
| Conv 10_1 | 1 x 1 x 128 |
| Conv 10_2 | 3 x 3 x 256 / padding = 1, stride = 2 |
| Conv 11_1 | 1 x 1 x 128 |
| Conv 11_2 | 3 x 3 x 256 / padding = 1, stride = 2 |
Training
Default box는 크기, 종횡비의 조합으로 정의된다. 각 피라미드 층마다 먼저 크기를 정의하고 이에 맞는 종횡비를 설정한다. 크기에 대한 정의는 다음과 같다.
\[s_{k} = s_{min} + \frac{s_{max}-s_{min}}{m-1}(k-1), \qquad k \in \left[1,m\right]\]\(m\)은 feature pyramid의 수를 나타내는 데 논문에서는 총 6개 이며 최소 크기와 최대 크기는 각각 0.2, 0.9로 정의되었다. 그리고 각 종횡비 \(a_{r} = \left\{ 1,2,3,\frac{1}{2},\frac{1}{3}\right\}\)이며 추가로 각 크기마다 종횡비가 1이고 크기가 \(s_{k}'=\sqrt{s_{k}s_{k+1}}\)인 box를 추가한다. default box가 4개인 pyramid는 3과 1/3 종횡비를 제외한다. 크기와 종횡비에 따른 default box의 center, width, height는 아래와 같다.
\[w_{k}^{a} = s_{k}\sqrt{a_{r}} \qquad h_{k}^{a} = s_{k}\sqrt{a_{r}} \\ (c_{x},c_{x}) = \left( \frac{i+0.5}{\left| f_{k}\right|},\frac{j+0.5}{\left| f_{k}\right|} \right) \qquad\]\(\begin{vmatrix} f_{k} \end{vmatrix}\)는 \(k\)번째 feature map의 사이즈(가로 혹은 세로)이다.
논문에서는 예측된 8732개의 default 박스에 대해 ground truth와 0.5이상의 IOU를 가질 때 이 default box는 매칭되었다고 표현하며 i번째 default box와 j번째 ground truth box의 매칭 유무를 다음과 같이 나타낸다. 매칭이 되었을 때는 1(Positive sample), 매칭이 되지 않았을 때는 0(Negative sample)이라는 뜻이다. 이렇게 단순하게 정의하는 쪽이 오히려 가장 큰 IOU를 나타내는 sample에 대해 계산하는 것 보다 더 높은 score를 예측한다고 한다.
\[x_{i,j}^{p} = \left\{1,0\right\}\]matching 단계에서 조심할 부분은 Positive sample과 Negative sample의 개수가 너무 편향되면 안된다는 것이다. 각 confidence score에 대해 loss를 먼저 계산한 뒤 Negative sample을 작은 순으로 정렬하여 Positive와 Negative가 1:3이 되도록 조절한다. 그리고 나머지 sample들의 loss는 최종 loss에 합산하지 않는다. 이 부분을 논문에서는 “Hard negative mining”이라고 표현했다.
SSD의 목적함수는 다음과 같다.
\[L(x,c,l,g) = \frac{1}{N} (L_{conf}(x,c) + \alpha L_{loc}(x,l,g))\]- \(L_{conf}(x,c)\) : Loss function for confidence score
- \(L_{loc}(x,l,g)\) : Loss function for localization
- \(c\) : Confidence score
- \(l\) : Predicted box
- \(g\) : Bounding box of ground truth
- \(\alpha\) : Weight tum of loss
- \(N\) : Number of matched box, loss = 0 if N=0.
그리고 각 loss에 대한 식은 다음과 같다.
\[L_{conf}(x,c) = -\sum_{i \in Pos}^N x^{p}_{ij}log(\hat{c}_{i}^{p}) - \sum_{i \in Neg}log(\hat{c}_{i}^{0}) \qquad where, \hat{c}_{i}^{p}=\frac{exp(c_{i}^{p})}{\sum_{p}exp(c_{i}^{p})}\]식으로 보면 거창한데 label+1개의 feature에 대해 softmax를 실행하고(식에 where에 해당하는 부분) negative sample(background class)과 positive sample에 대한 cross entropy의 합이다.
\[L_{loc}(x,l,g) = \sum_{i \in Pos}^{N} \sum_{m \in \left\{cx,cy,w,h \right\}} x_{i,j}^{k} smooth_{L_{1}}(l_{i}^{m} - \hat{g}_{j}^{m}) \\ \hat{g}_{j}^{cx} = (g_{j}^{cx} - d_{i}^{cx})/d_{i}^{w} \qquad \hat{g}_{j}^{cy} = (g_{j}^{cy} - d_{i}^{cy})/d_{i}^{h} \\ \hat{g}_{j}^{w}= log(\frac{g_{j}^{w}}{d_{i}^{w}}) \qquad \hat{g}_{j}^{h}= log(\frac{g_{j}^{h}}{d_{i}^{h}})\]- \(d\) : Default box
- \(g\) : Bounding box of ground truth
- \(\hat{g}\) : Box to be predicted
- \(l\): Predicted box
objective function 자체는 Faster R-CNN과 동일하다.
나머지 정보는 아래와 같다.
- Optimizer : SGD, 0.9 momentum, 0.0005 weight decay
- Batch size : 32
- Learning rate : \(10^{-3}\)
-
Conv weight initialize : pretrained model, xavier
- Data augmentation
- 전체 이미지
- 50% 확률로 수평반전
- IOU가 최소 0.1, 0.3, 0.5, 0.7, 0.9인 샘플 패치 넣기
- 랜덤으로 정해진 패치 넣기
Result
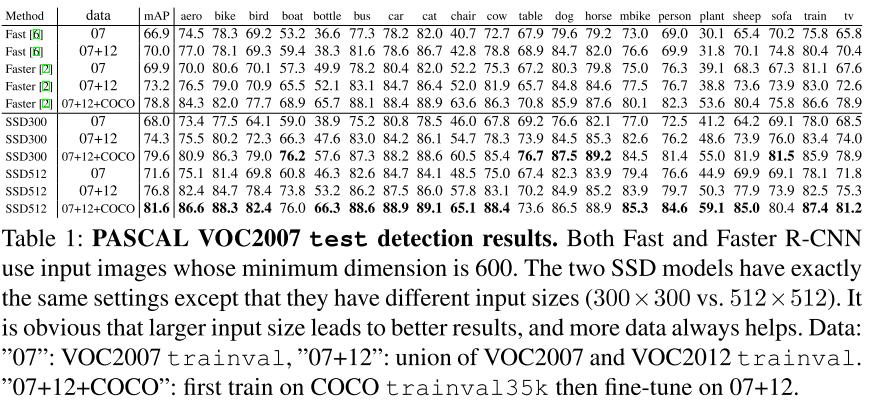
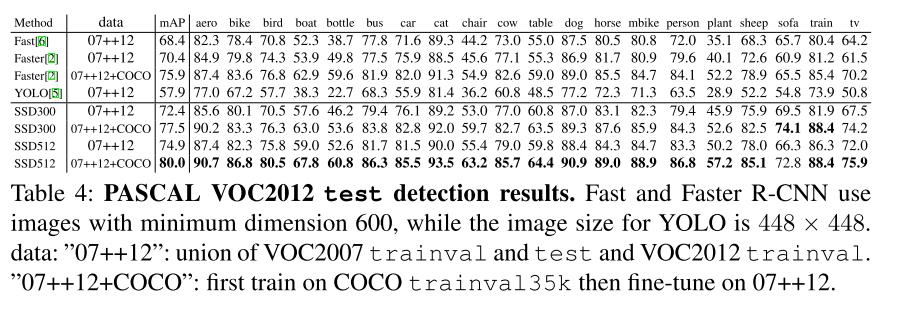
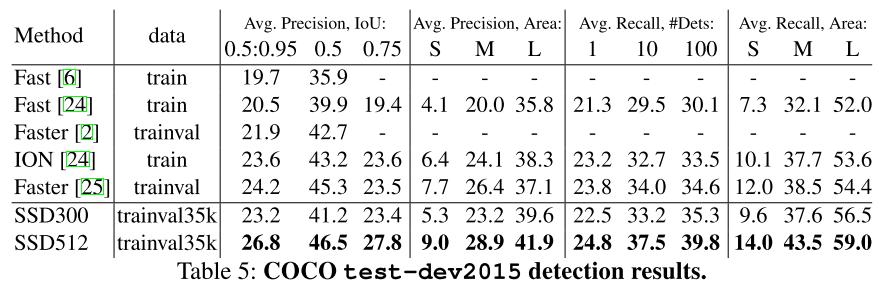
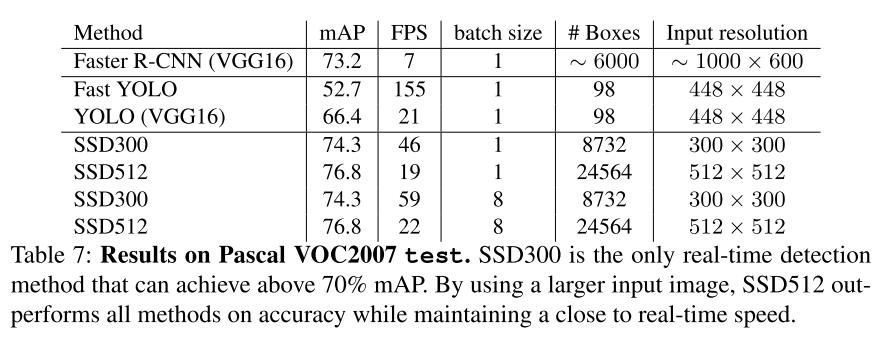
각 그림에서는 VOC2007, VOC2012, COCO 2015데이터 세트에서의 정확도와 VOC2007에서의 FPS를 보여준다. 결과에서 알 수 있듯 SSD는 높은 정확도와 빠른 처리속도라는 두 마리의 토끼를 잡을 수 있었다.
Reference
[1] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, and S. Reed. SSD: Single shot multibox detector. In ECCV, 2016.
Comments