“Fast R-CNN”은 2015년 ICCV에 발표되었다. Fast R-CNN 은 SPPnet의 아이디어를 차용해 R-CNN을 개량하였고 이로인해 SPPnet과 R-CNN보다 빠른 학습속도, 추론속도 및 높은 정확도를 획득하였다.
Fast R-CNN
R-CNN과 SPPnet에는 다음과 같은 문제를 가지고 있다.
- 학습이 multi-stage pipeline을 가지고 있다. pre-trained된 모델을 finetuning, 이후 softmax layer를 SVM으로 대체하고 finetuning, 이후 bounding box를 학습한다.
- 학습에 공간과 시간이 많이 든다. SVM과 bounding box를 학습시키기위해, 각 이미지에서 추출된 feature들을 디스크에 저장해야 한다.
- 추론속도가 느리다.
이를 해결한 Fast R-CNN은 다음과 같은 특징을 갖는다.
- R-CNN, SPPnet 보다 더 높은 정확도(mAP)를 갖는다.
- multi-task loss를 사용해 학습 단계를 단순화 하였다.
- feature를 저장하기 위한 별도의 disk 공간을 필요로 하지 않는다.
Arichtecture
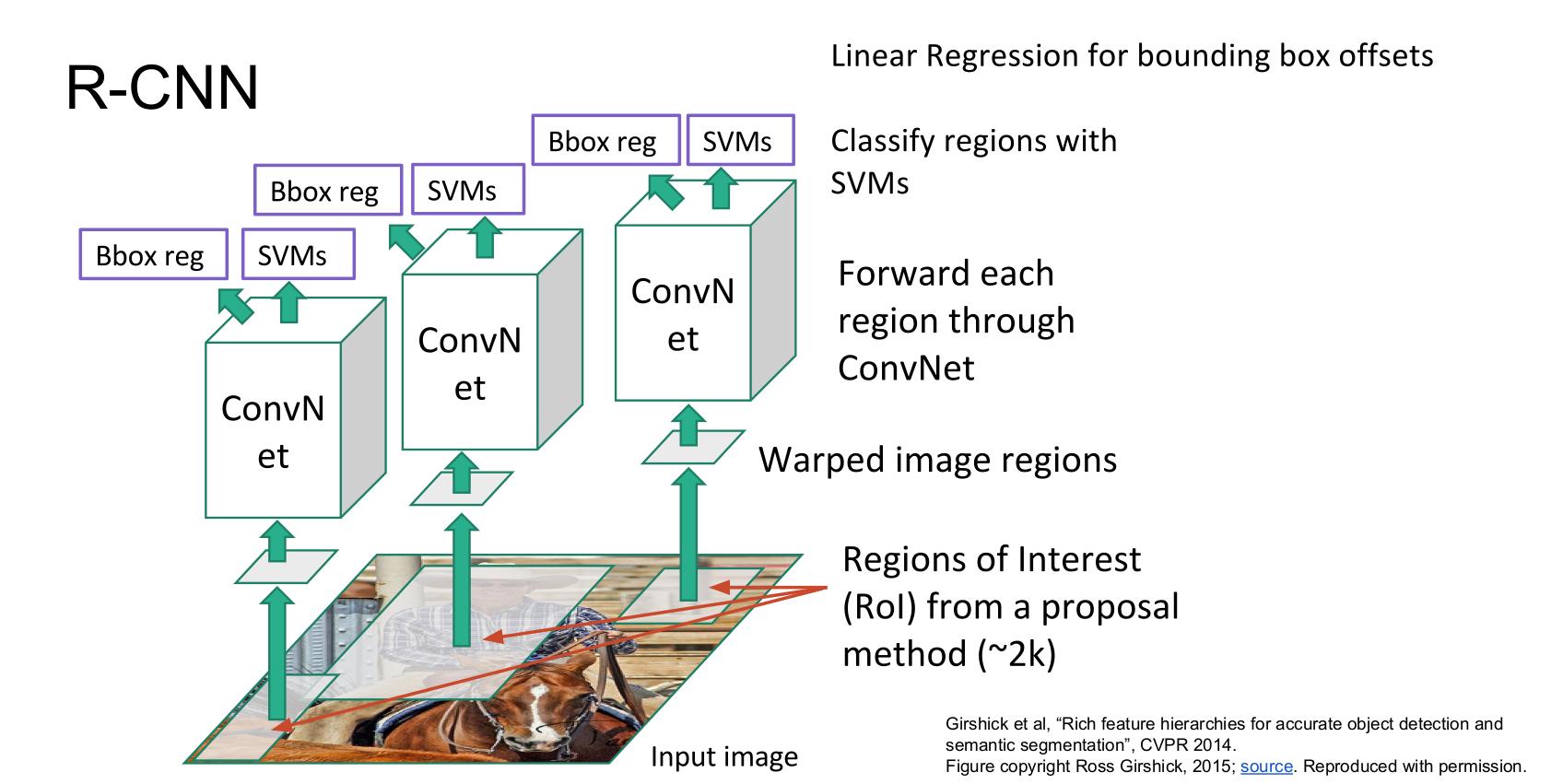
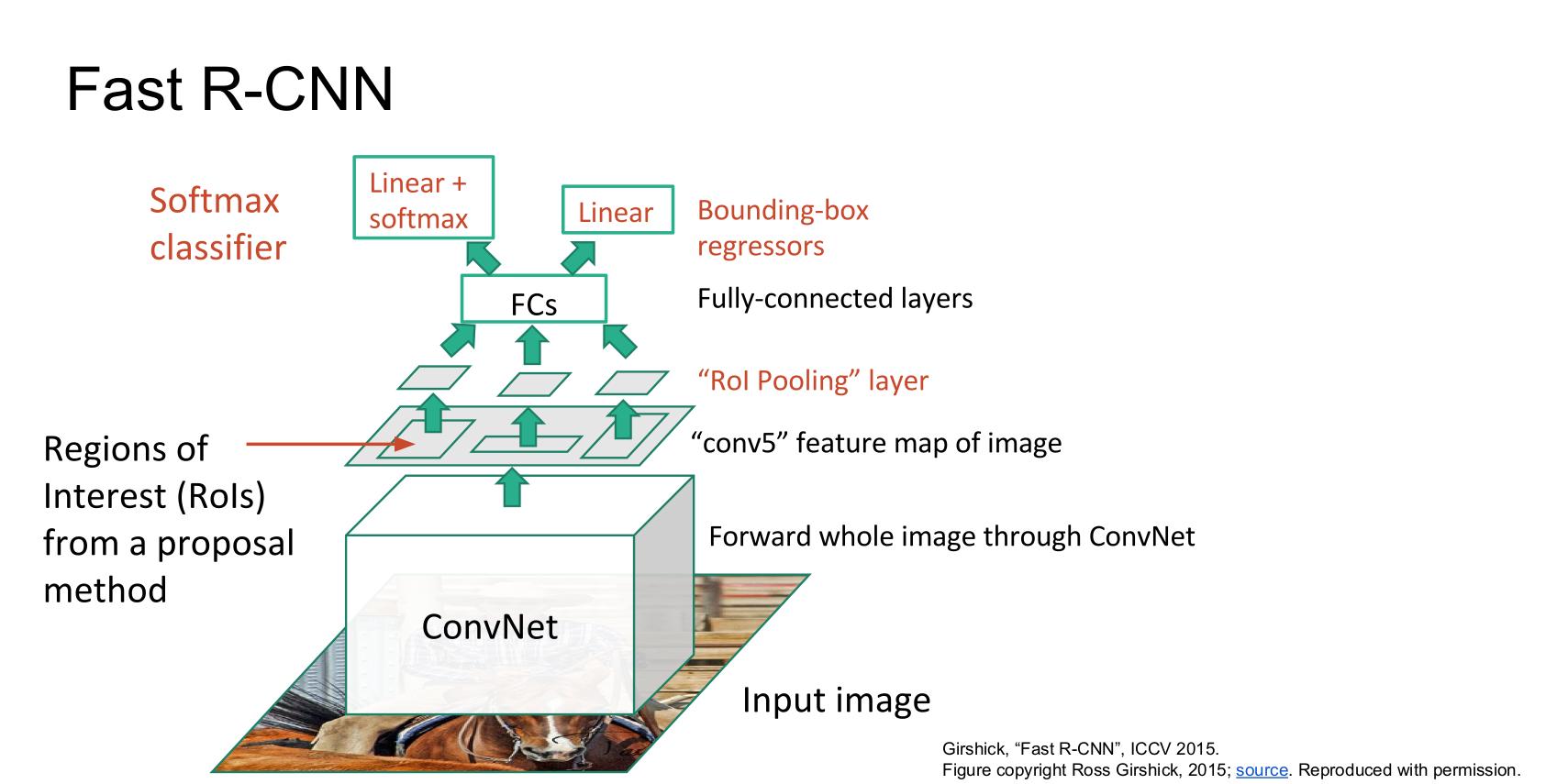
위 사진은 각각 R-CNN과 Fast R-CNN에 대한 그림이다.
두 구조의 가장 큰 차이점은 언제 Region proposal을 수행하냐이다. R-CNN은 CNN으로 입력되기 전 약 2000개의 Region proposal 영역이 입력으로 들어가는데에 반해 Fast R-CNN은 입력 이미지에 대해 selective search를 수행하고 하나의 이미지가 Conv Net을 거친 이후 feature map에서 selective search를 통해 찾은 각각의 ROI에 대해 진행한다. 그런데 이 ROI 영역들은 모두 다른 크기를 가지고 있기 때문에 ROI pooling을 통해 고정된 크기의 벡터로 변환한다.
이후 고정된 크기의 feature들은 2개의 fc layer를 거치는데 하나는 배경을 포함한 K개의 class에 대한 것이며 나머지 하나는 bounding box에 대한 것이다.
SPP(Spatial Pyramid Pooling)과 ROI pooling
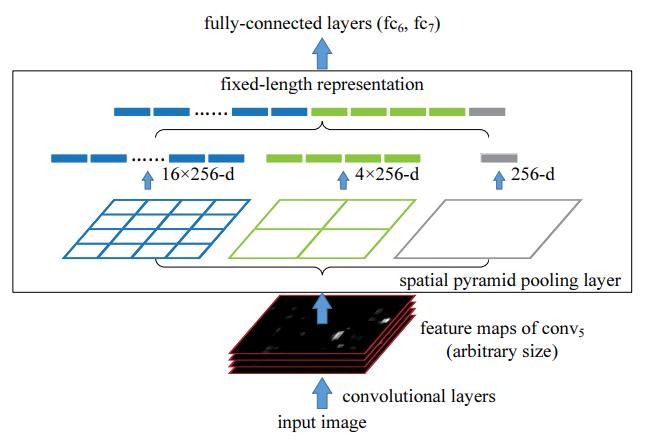
spatial pooling layer는 위와 같다. Conv-layer의 마지막 출력과 첫 Fc-layer 사이에 feature map을 전체 영역으로 해서(bin=1) max pooling, feature map을 4 등분(bin=4)해서 max pooling, feature map을 16 등분(bin=16)해서 max pooling하면 입력 이미지 크기에 무관하게 항상 (16+4+1) 크기의 고정된 벡터가 생긴다. 이를 fc-layer의 입력으로 하므로써 다양한 크기의 이미지를 입력으로 받을 수 있는 네트워크가 생성된다.
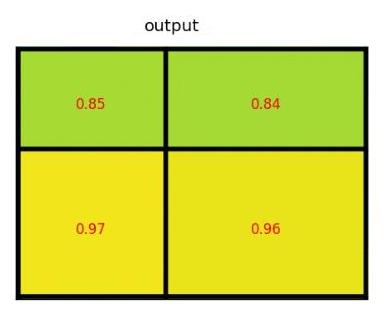
ROI pooling은 SPP pooling의 하위 개념이다. ROI 영역에 대해 원하는 크기 (e.g. 7 x 7)로 bin을 생성해 max pooling을 수행한다. 논문에서는 각 ROI 영역의 좌측 상단 좌표를 (r,c), ROI 크기를 (h,w)로 표현 했으며 만들고자 하는 고정된 크기를 H x W 로 표현한다. ROI 영역을 (h/H x w/H)의 크기를 갖는 하위 영역으로 만들면 총 7x7의 영역이 생기며 각 영역에 대해 maxpooling을 수행하는 것이다.
Training
Fast R-CNN에서도 pre-trained model을 사용하고 이후 fine-tuning을 한다. fine-tuning 시에는 3가지를 변경한다.
- 마지막 max pooling layer는 ROI pooling으로 변경
- 마지막 fc-layer를 각각 bounding box regression을 수행하는 부분과 K+1개의 class를 가지는 2개의 layer로 만든다(둘은 직렬로 연결되지 않고 병렬형태이다).
- 네트워크의 인풋은 이미지 리스트와 ROI 영역 리스트이다.
기존의 SPPnet과 R-CNN에서는 ROI영역이 서로 다른 training sample에서 추출된 경우 학습이 비효율적으로 일어난다고 한다. 반면, Fast-RCNN은 forward와 backward 계산시에 연산과 메모리가 공유하는 점에서 효율적이라고한다.
Fast-RCNN에서는 2개의 이미지에서 총 64개의 ROI영역(N=2, R=128, 각 이미지로부터 sample = R/N 개)을 샘플링한다. 64개 중 25%는 0.5이상의 IOU를 갖는 영역을 선택하고(\(u \ge 1\)) 나머지는 \(\left[0.1,0.5 \right)\)의 IOU를 갖는 영역을 선택한다(background, \(u = 0\)). 같은 이미지로부터 ROI들이 상호 연관되어 있어 학습 수렴속도가 느리지 않을까 걱정했지만 R-CNN보다 적은 SGD iteration을 사용했음에도 좋은 결과를 보여 이에 대해서는 걱정하지 않아도 된다고 한다.
Multi-task loss
Fast R-CNN은 두 가지의 loss function을 사용한다.
첫 번째는 classfication에 대한 loss이며, 다른 논문과 마찬가지로 cross-entropy를 사용한다.
\[L_{cls}(p,u) = -logp_{u}\]여기서 p는 예측한 확률, u는 라벨이다.
두 번째 loss는 bounding box에 대한 loss이다. 각 t는 이전에 포스팅한 R-CNN글에서 \(\hat{G}\)에 해당한다.
\[L_{loc}(t^{u},v)= \sum_{i \in \left\{ x,y,w,h\right\}} smooth_{L_{1}}(t_{i}^{u}-v_{i})\]여기서 특이하게 \(smooth_{L_{1}}\)을 사용하는데 이는 \(L_{2}\) loss보다 outlier에 덜 민감해 exploding gradient를 방지할 수 있기 때문이라고 한다. \(smooth_{L_{1}}\)은 다음과 같이 정의된다.
\[smooth_{L_{1}}(x) = \begin{cases} 0.5x^2 \qquad if \left| x\right| <1 \\ \left| x\right| - 0.5 \quad otherwise, \end{cases}\]최종 loss function은 다음과 같이 정의된다.
\[L(p,u,t^{u},v) = L_{cls}(p,u)+\lambda \left[ u \ge 1\right]L_{loc}(t^{u},v)\]여기서 \(u \ge 1\)은 label된 class에 대해서 수행하겠다는 표시이며 background로 예측된 ROI 영역에 대해서는 \(u\)가 항상 0이다. 또한, \(\lambda\)는 두 loss 간의 weight를 설정하기 위한 하이퍼파라미터이다. 본 논문에서는 1로 설정되었다.
Backpropagation through RoI Pooling Layer
이전 SPP Net에서는 SPP 이후의 fc layer들만 fine-tunning을 했다고 한다. 그래서 이 논문에서는 이미지로부터 특징을 뽑는 가장 중요한 CNN까지 학습이 전달될 수 있다는 것을 강조한다.
ROI pooling layer를 backward function은 다음과 같다.
\[\frac{\partial L}{\partial x_{i}} = \sum_{r} \sum_{j} \left[i=i^{*}(r,j) \right] \frac{\partial L}{\partial y_{rj}}\]여기서 \(x_{i}\)는 CNN을 통해 추출된 feature map의 하나의 피쳐 값, \(y_{rj}\)는 \(i=i^{*}(r,j)\)는 r번째 ROI영역에서 j번째 sub window의 output을 뜻한다. 즉 해당 \(x_{i}\)가 영향을 주려면 (r,j) 영역에서 최대값이어야 한다. 이후와 이전의 값은 모두 동일하게 구할 수 있기 때문에 \(x_{i}\)에 대한 중첩만 확실히 하면 된다.
초기화와 하이퍼파라미터, optimizer에 대한 정보는 다음과 같다.
- classification과 bounding-box regression 초기화 : 평균 0, 분산 각각 0.01과 0.001을 갖는 정규분포
- Bias 초기화 : 0
- Optimizer : SGD(momentum = 0.9, decay = 0.0005)
- Default learning rate : 0.001
- Iteration : VOC07 또는 VOC12에서 30k번 학습, 이후 learning rate를 0.0001로 낮춘 다음 10k번 학습
- Data augmentation : 수평 반전, random pyramid scale sample (scale invariance를 학습하기 위해)
Truncated SVD
속도를 줄이기 위한 전략으로 Truncated SVD를 사용할 수 있다. Truncated SVD는 \(u \times v\) 크기의 행렬을 다음과 같이 \(u \times t\), \(t \times t\), \(t \times v\)의 크기를 갖는 행렬로 분해하는 방법이다.
\[W \approx U \Sigma_{t}V^{T}\]이 방법을 사용하면 파라미터의 수를 \(uv\)에서 \(t(u+v+t)\)로 바꿀 수 있으며 t가 매우 작은 경우 상당한 양을 줄일 수 있다. 논문에서 \(\Sigma_{t}V^{T}\)와 \(U\)를 나누고 bias는 \(U\)에 적용했다고 한다.
Result
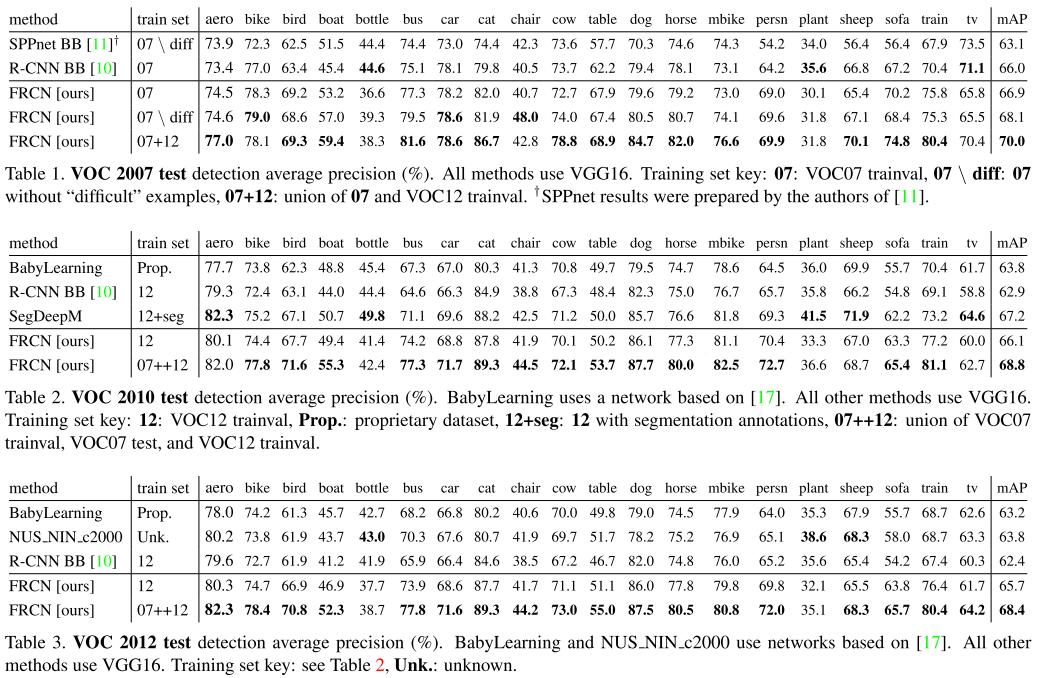
Fast R-CNN은 VOC 2010,2012,2007에서 더 높은 정확도를 보여준다.
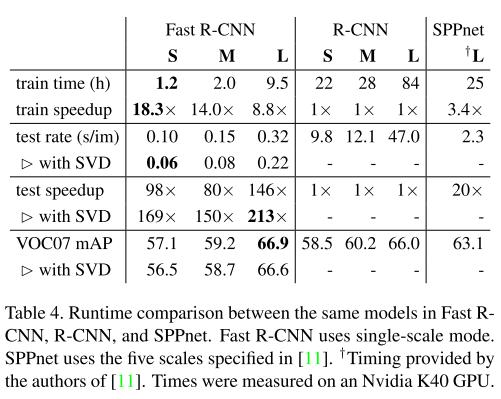
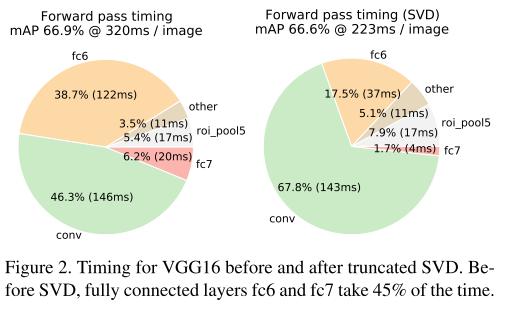
위 table은 논문의 주 목적인 Fast R-CNN이 R-CNN과 SPPnet에 비해 얼마나 빠른가를 보여준다. 표의 숫자는 R-CNN 기준으로 얼마나 빠른지를 보여준다. 이 표를 통해 월등히 빠른 속도에 반해 더 높은 정확도를 획득했음을 강조한다. 또한, truncated SVD를 이용하면 약 0.3 mAP의 정확도가 낮아지지만 30%의 속도 향상을 얻을 수 있다. 2번째 그림은 truncated SVD를 이용했을 때 각 layer 별로 얼마나 속도가 차이나는지 보여준다.
Reference
[1] R. Girshick. Fast R-CNN. In ICCV, 2015.
[2] R. Girshick. J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014.
[3] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014.
Comments