Before Review
VGG와 마찬가지로 GoogLeNet에서는 NIN(Network in Network)[1]에서 소개한 1x1 convolution을 사용하는 데, 이해하면서 중간에 혼동했던 내용을 정리한다.
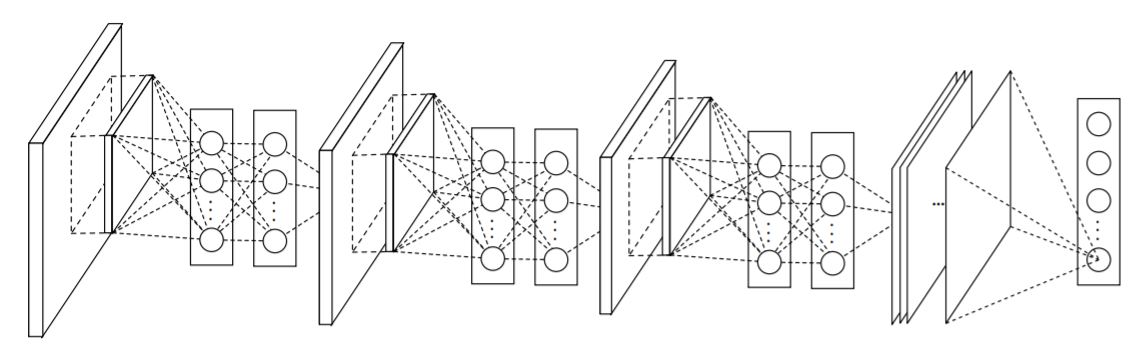
아래는 NIN의 모델이다. 모델의 비선형성을 증가시키기 위해 Convolution 연산 사이에 MLP를 추가한다.
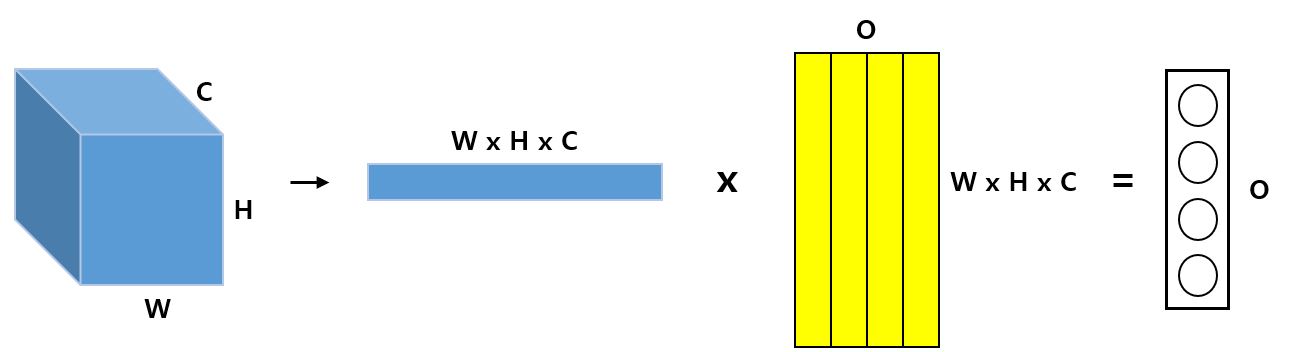
이 부분을 이해할 때 혼동이 왔었는데 순서의 문제이다. 일반적으로 CNN에서 FC layer를 사용할 때 아래의 사진과 같이 이미지를 1차원 배열로 Reshape을 하고 \(W \times H \times C\) 개의 가중치를 가지는 1차원 배열이 Output 노드의 개수(사진에서는 O) 만큼 존재해 행렬연산으로 총 O개의 노드가 생성된다.
그런데 논문에서 나오는 수식은 다음과 같다.
\[f_{i,j,k_{1}}^1 = max({w_{k_1}^1}^T x_{i,j} + b_{k_{1}},0) \\ ... \\ f_{i,j,k_{n}}^n = max({w_{k_n}^n}^T {f_{i,j}}^{n-1} + b_{k_{n}},0)\]여기서 \(x_{i,j}\)는 i,j 위치에 있는 픽셀에 대한 값이고 f는 n번째 MLP에 의한 결과이다.
이 연산을 그림으로 표현하면 다음과 같다.
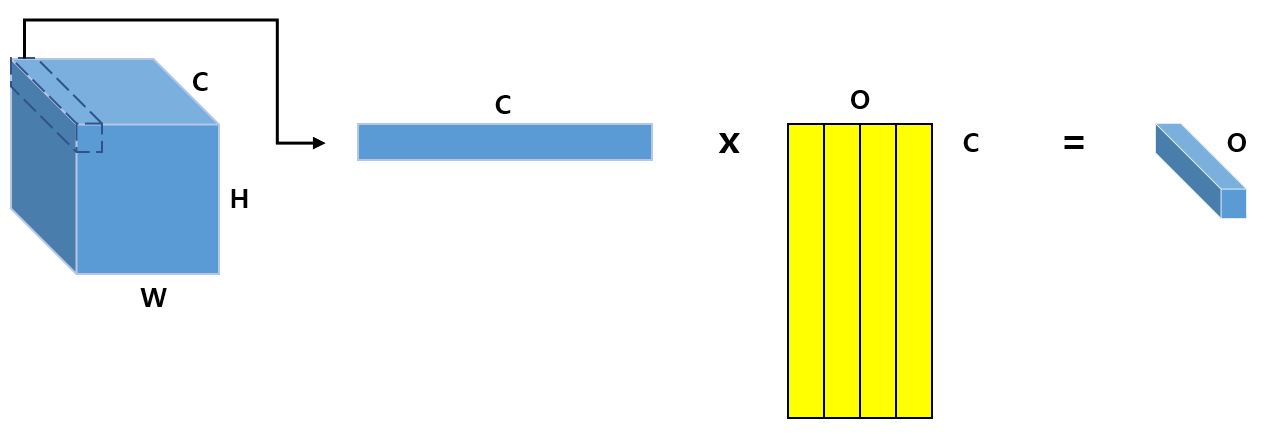
한 픽셀에 대해 채널 개수만큼의 가중치를 가지는 1차원 배열이 O개 만큼 존재하고 행렬 연산으로 O개의 노드가 생성되는 데 이때의 O는 새로운 Output의 Channel이 된다.
다시말하면, CNN 연산을 거치고 나온 feature map의 동일한 채널내의 모든 픽셀은 같은 가중치에 의해 곱해지고 O개의 동일한 size의 feature map이 생성되며 O는 새로 생성된 feature map의 채널과 같이 볼 수 있다. ReLU와 같은 Activation Function에 의해 비선형성이 증가된다.
위 과정은 1x1 Convolution 연산과 똑같다. 1x1 Convolution은 1x1개의 가중치를 가지는 필터가 O개 만큼 있고 연산시에 동일한 채널에 있는 feature map은 동일한 커널에 의해 계산된다.
GoogLeNet
GoogLeNet은 2014년 ILSVRC에서 1등을 차지한 모델이다.
VGG와 마찬가지로 어떻게 모델을 설계하면 더욱 깊어질 수 있는지(Deeper) 뿐 아니라 각 layer에 있는 Unit의 수도 늘리기 위해(Wider) 고민한 논문이다.
GoogLeNet을 검색하면 아래와 같은 사진이 많이 나오는데 구글의 연구팀이 인셉션 영화의 깊은 곳으로 들어가 더 중요한 정보를 얻는다는 컨셉을 차용했기 때문이다. 그래서 GoogLeNet에는 Inception이라는 다른 이름이 붙는다. 이 논문은 Inception의 처음 버전인 Inception v1에 대한 논문이다.

일반적으로 네트워크를 Deeper, Wider 하게 설계하면 성능을 향상 시킬 수 있다는 게 자명해졌는데 2가지의 이유로 어려운 문제가 되었다.
- 일반적으로 Deeper, Wider 하다는 것은 더 많은 수의 parameter를 의미하고 이는 Overffitting의 가능성을 키운다. 특히, train set에서 label 된게 제한적일 경우 확률은 더욱 올라간다.
- 더 많은 수의 parameter로 인해 연산량은 대폭 증가하게 된다.
해결방안 중 하나는 Sparse Connectivity로 서로 높은 관련성을 가진 노드들 끼리만 연결되도록 하면 연산량과 파라미터는 줄게 된다는 것이다(대표적으로 Dropout).
하지만, 실제로는 Dense Matrix 연산보다 Sparse Matrix 연산에 대한 연구가 많이 발전되지 않아 더 큰 자원을 사용한다.
여기서 구글은 어떻게 노드 간의 연결을 줄이면서, 행렬 연산은 Dense 연산을 하도록 처리하는가에 대해 집중하였다.
Architecture
아래 사진은 GoogLeNet의 전체적인 구조도이다.
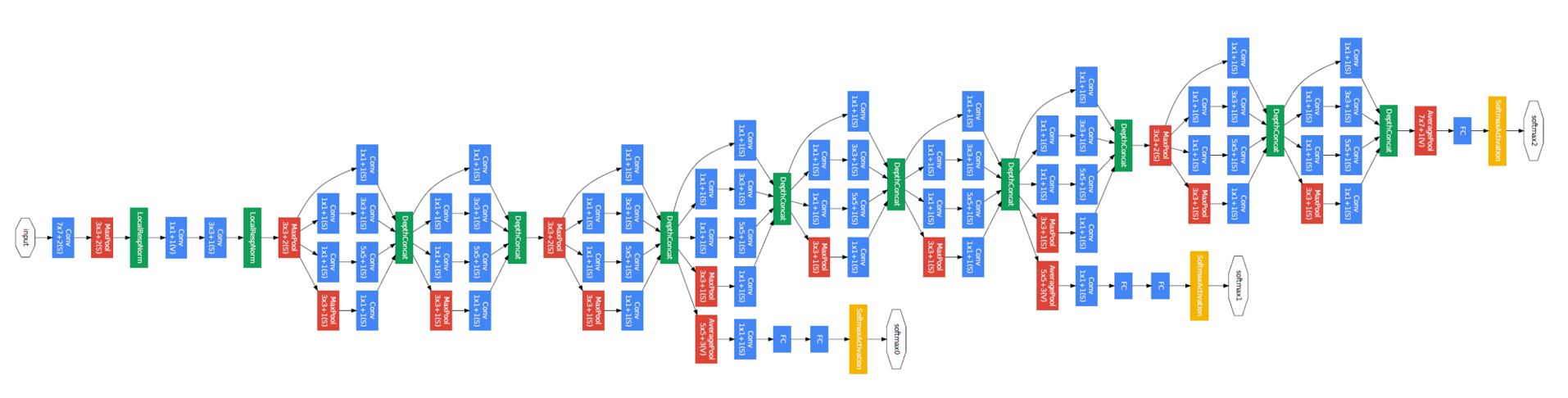
위 사진에서 파란색 부분은 layer, 빨간색 부분은 pooling, 노란색 부분은 softmax, 초록색 부분은 LRN 혹은 Depth concatenation이다.
전체 구조는 다음과 같이 Stem, Inception module, Auxiliary classifiers, Output classifier 네 부분으로 나뉜다.
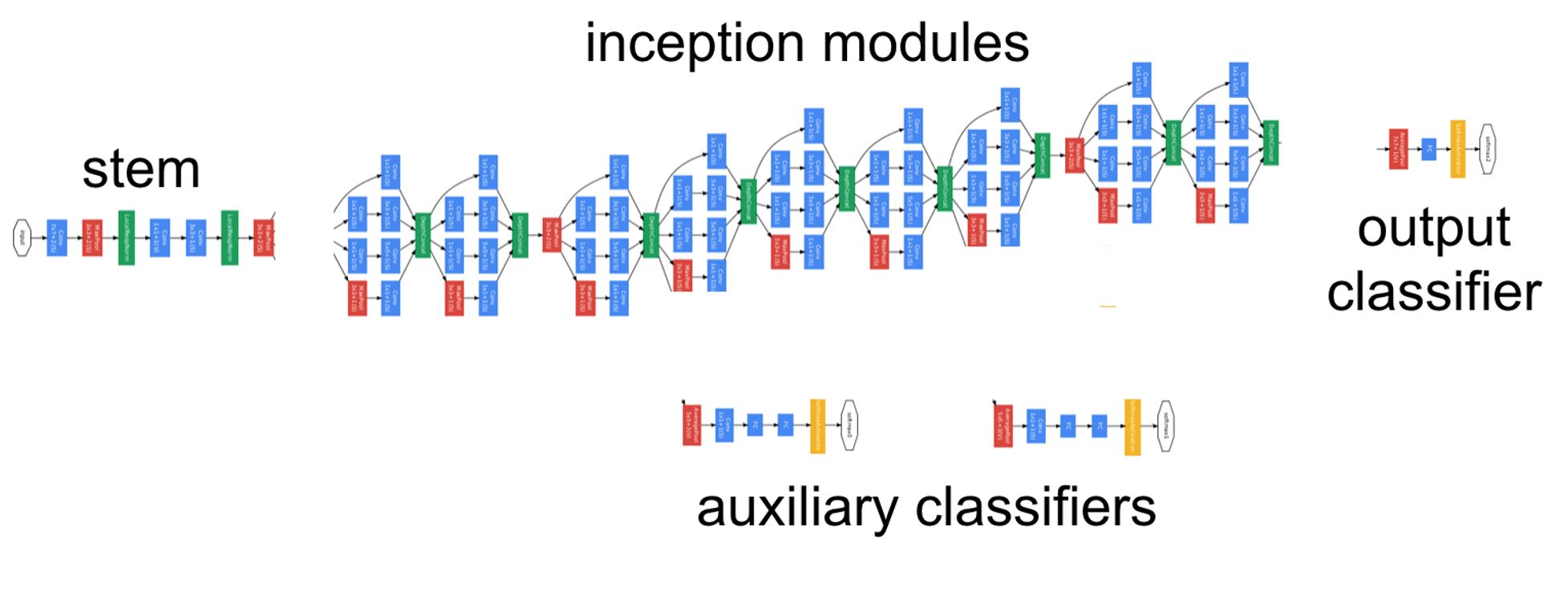
Stem
Stem 부분은 사실 크게 설명할 부분이 없다. 일반적인 CNN 구조를 띄고 있다. 이 구간에서는 Inception Module이 큰 효과가 없어 제외하였다고 한다. 이 부분은 Inception v3까지 유지 되었다.
Inception Module
Sparse Connectivity와 Dense 연산에 대한 아이디어는 아래 사진의 Inception Module에 있다.
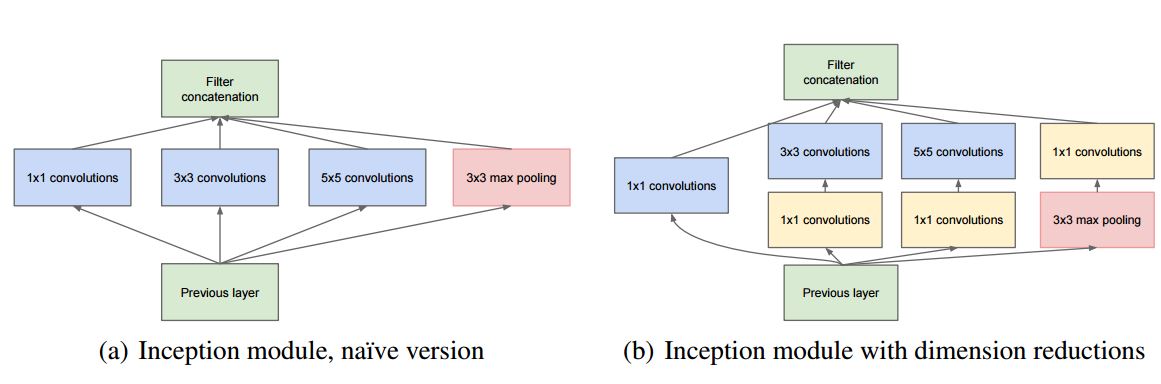
왼쪽의 그림이 맨 처음 설계된 모듈의 구조이다. 1 x 1, 3 x 3, 5 x 5, pooling 구조를 병렬로 설계해 다양한 scale의 feature를 뽑기에 적합한 구조이다. 맨 처음의 목적인 Wider한 네트워크가 설계된 것이다.
하지만 이 구조에는 문제점이 있다. 3 x 3, 5 x 5의 convolution을 적게 사용하더라도 filter가 많아지면 그만큼 연산량이 급증하게 되는 것이다.
그리고 pooling의 경우 conv layer와 다르게 채널의 수를 그대로 유지해야 하는데 4개를 concatenation했다는 것은 아래 layer로 갈 수록 점점 filter가 급증할 수 밖에 없고 4가지 특징의 비율을 맞추기 어려운 구조이다(이건 개인적인 분석이긴 하다).
이후에 바뀐 구조가 오른쪽 구조이다. pooling 이후와 3x3, 5x5 이전에 1x1 conv가 추가되었는데 1x1 convolution을 사용하게 되면 위에 NIN 부분에서 설명한 비선형성을 증가시키는 것 외에도 dimension reduction이 가능하다는 장점이 있다.
참고로 concatenation을 하기위해서는 feature map의 크기가 동일해야 하므로 pooling에도 padding이 들어간다.
이렇게 전체적으로 network 상의 연결은 줄이면서 (Sparsity), 세부적인 행렬 연산에서는 최대한 Dense한 연산을 하도록 설계되었다.
Classifier
GoogLeNet은 특이하게 Classifier 부분이 3개로 되어있는데 마지막 layer를 제외한 중간 2개의 classifier(Auxiliary classfiers)는 gradient vanishing 문제를 염두에 두고 중간 값을 backpropagation하기 위한 것이다. auxiliary classifier는 train시에만 사용되고 inference time에는 관여하지 않으며 train시에도 각각 0.3의 가중치를 가진다(마지막 layer는 1의 가중치를 갖는다.).
Arichtecture table
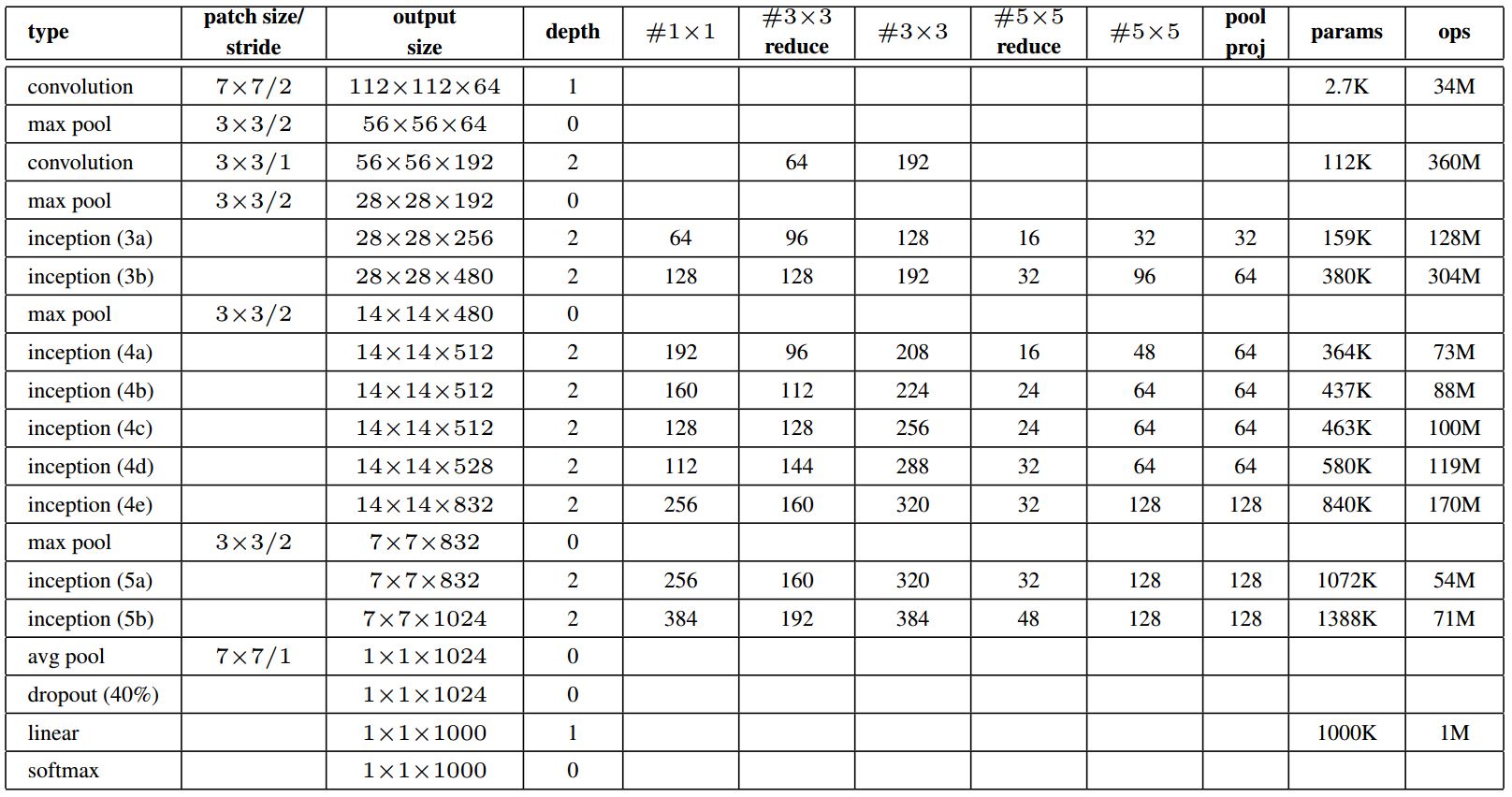
위 사진은 Arichtecture의 세부 설정들을 보여주는데 auxiliary classifier의 경우 표에는 빠져있다. auxiliary classifier는 (4a)와 (4b) 사이, (4d)와 (4e)사이에 있으며 5x5/3 Avg pool, 1x1x128 conv, 1024 fc layer, 0.7 Dropou, 1000 fc layer, softmax 순으로 구성되어있다.
Train
- Optimizer : Asynchronous SGD (momentum = 0.9)
- Learning rate : 8 epoch 마다 4% 감소
- Augmentation : 이미지 사이즈를 8%~100%, 4:3 또는 3:4 비율 랜덤하게 조절한 후 crop. Photo metric distortion이 overfitting 방지에 유용하다고 한다(Andrew Howard).
Test
Classification
test시에는 7개의 동일한 모델을 이용해 ensemble prediction을 수행했고 cropping 방식을 Alex net보다 더 적극적이게 했다.
먼저 (256,288,320,352) size로 image를 resize 하고 [left/ center/ right] 혹은 [top / center / bottom]을 crop한 이후 모서리 4개, 중앙을 224크기로 crop한 것과 이 자체이미지를 224로 resize한 이미지들과 horizon flipped된 이미지들(총 4 x 3 x 6 x 2 = 144)로 평가한다.
최종 예측에서는 각 이미지들에 대한 softmax probability를 평균하여 얻는다.
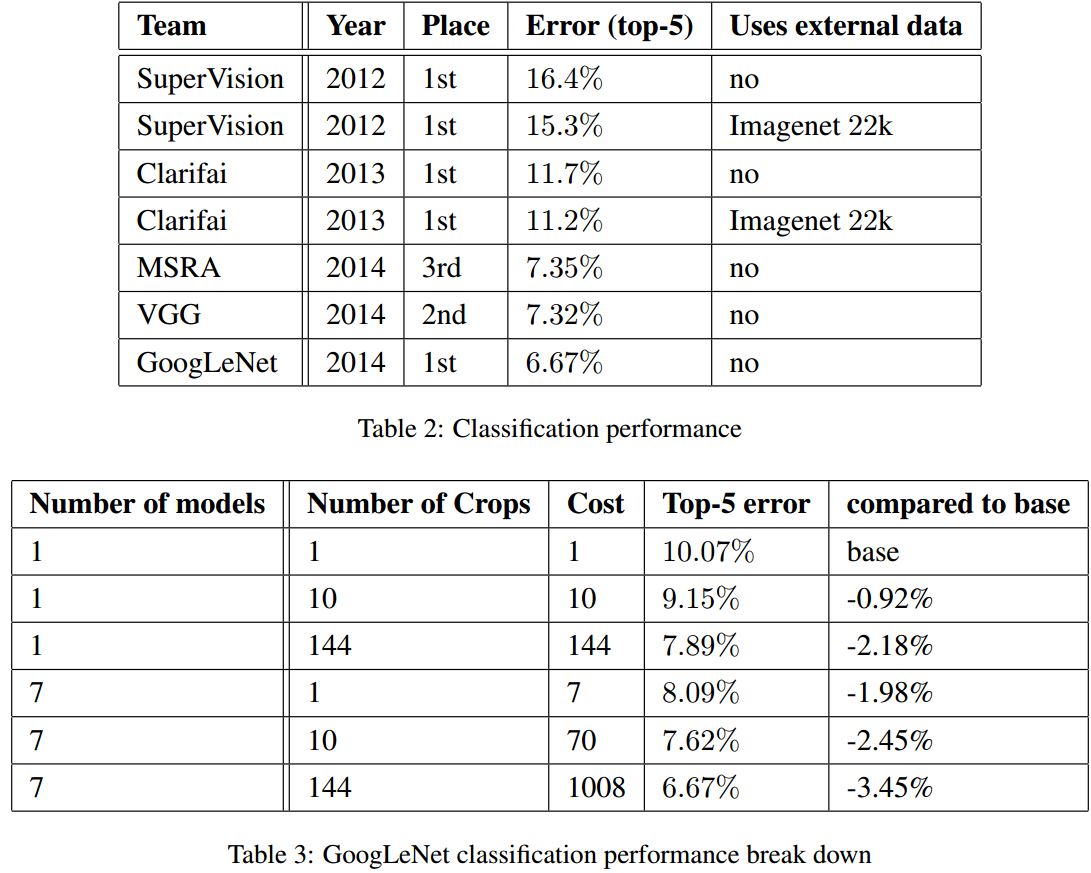
아래의 첫 번째 사진은 classification에 대한 결과이고 그 아래는 crop과 모델 수에 따라 평가를 한 결과이다.
Detection
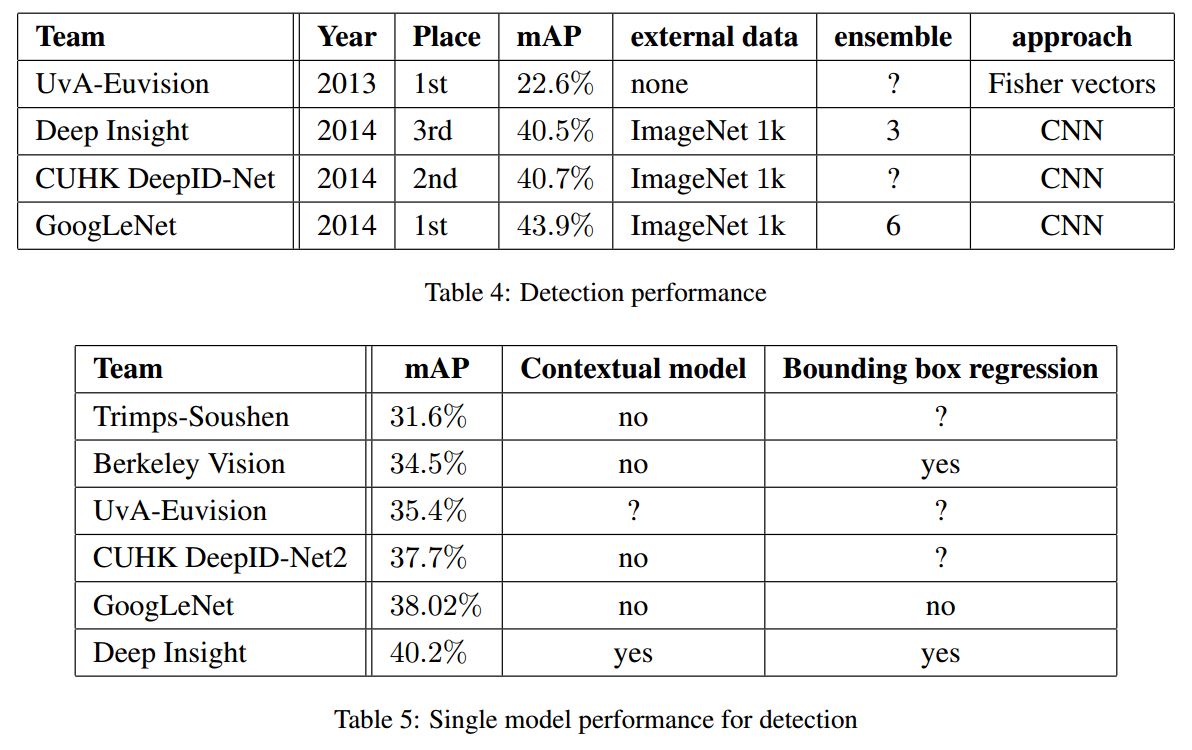
GoogLeNet의 detection 접근 방식은 R-CNN과 비슷하며, region classifier를 Inception model로 보강했고 region proposal step은 object bounding box의 recall을 더 높이기 위해 multi-box prediction을 사용한 selective search와 결합해 보강했다.
false positive의 수를 줄이기 위해 super pixel size를 2배 증가시켰고 이를 통해 selective search 알고리즘에서 얻어지는 proposal의 수를 반으로 줄였다.
그리고 multi-box에서 나온 200개의 region proposal을 더하여, 총 개수는 R-CNN에서 사용된 proposal의 60%인 반면, coverage는 92%에서 93%로 상승했다.
마지막으로 R-CNN과 달리 시간부족을 이유로 bounding box regression을 하지 않았는데도 6개의 모델을 ensemble하여 정확도를 40%에서 43.9로 상승시켰다.
Reference
[1] Min Lin, Qiang Chen, and Shuicheng Yan. Network in network. CoRR, abs/1312.4400, 2013.
[2] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015.
Comments