VGG는 2014년 Oxford 대학의 Visual Geometry Group에서 연구되었으며 2014 Image Net Challenge에서 2등의 성과를 냈다.
1등인 GoogLenet보다 구현하기 간편하다는 점에서 VGG가 많이 이용되었다.
VGG와 GoogLenet의 공통점은 모델의 layer를 깊게 쌓아 올리기 위해 연구되었다는 점이다.
Architecture
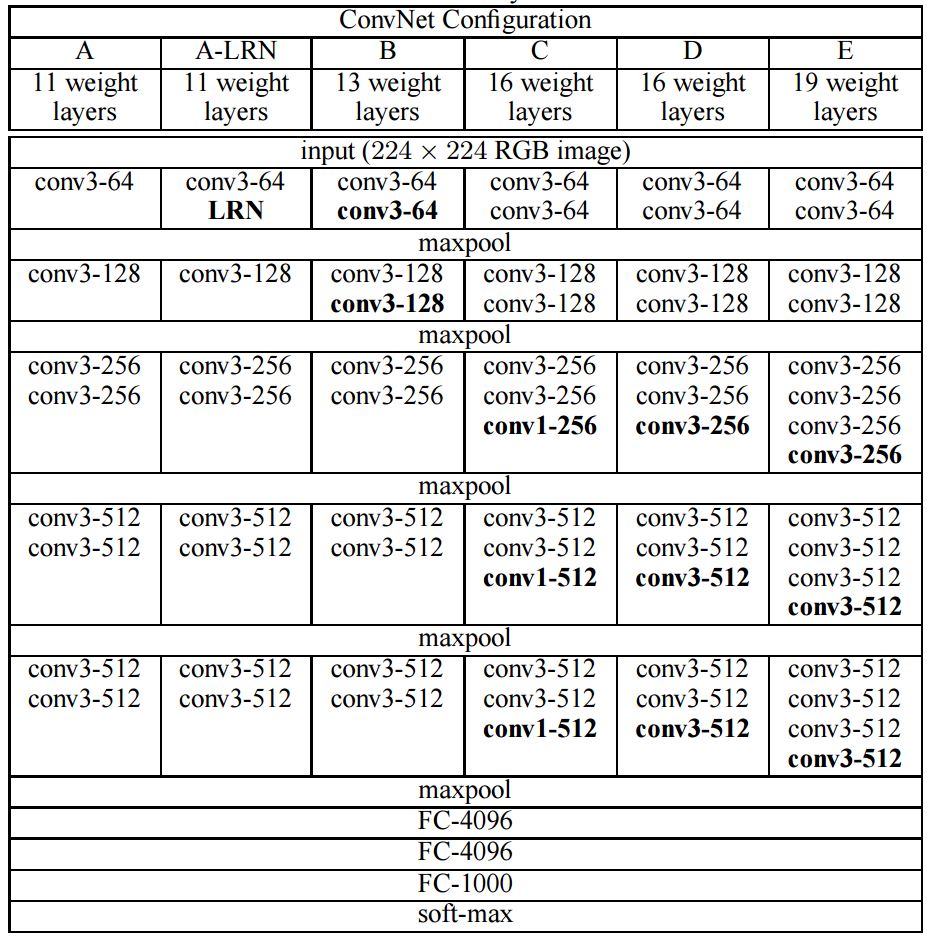
- 입력 이미지는 224 X 224 X 3 의 shape을 가진다.
- 전처리는 훈련 세트에서 계산된 평균 rgb 값을 각 픽셀에서 뺀다.
- Conv3은 3 x 3 크기의 커널을 갖는 Convolution layer.
- Convolution layer의 stride 1로 고정한다.
- Conv3에 대해서는 padding을 1로 한다 (Image shape을 유지하기 위해).
- Maxpooling은 2 x 2 kernel, 2 stride.
- LRN은 Alex net에서 사용한 Local Response Normalization을 뜻한다.
3 x 3 Convolution
VGG Net의 큰 특징중 하나는 다른 논문에서는 첫번째 레이어에서 11 x 11이나 7 x 7크기의 filter를 쓴 반면 3 x 3 크기의 filter만 등장한다는 것이다.
논문에서 주장하는 바에 따르면 다음과 같다.
-
5 x 5 filter의 receptive filter와 3 x 3 filter를 두 번 수행하는 것이 동일한 receptive field를 가지며, 7 x 7은 3 x 3을 3개, 11 x 11를 5개 사용한 것과 동일한 receptive field를 가진다.
- Convolution 연산 이후에 activation function을 추가함으로써 동일한 receptive field에 비선형성을 더 추가할 수 있다.
- 7 x 7 filter와 3 x 3 filter 3개의 파라미터의 수를 비교하면 각각 \(7^2 C^2\) , \(3^2 C^2 \times 3\)으로 동일한 receptive field에 대해 더 적은 연산이 들어간다.
1 x 1 Convolution
“Network in Network_Lin(2014)” 논문에서 소개된 방법으로, 본 논문에서는 receptive filed의 영향없이 비선형성을 증가시키는 방법으로 사용되었다.
Training
- Optimizer : Momentum
- Momentum factor : 0.9
- Weight decay : 0.0005
- Learning rate : 0.01, validation error rate가 줄지 않을 때마다 1/10 배
- Batch size : 256
- Epoch : 약 74 (정확히는 370K iteration)
Alex Net에 비해 파라미터가 많음에도 빠른 이유는 다음과 같은 이유로 추측했다.
- 더 깊은 net과 작은 필터 크기로 인한 암시적 정규화
- 특정 Layer의 가중치 초기화 (처음 네개의 conv layer들과 fully connected layer는 자비에르(Xavier 초기화[2] Glorot&Bengio로 표기된거는 처음봐서 순간 당황했었다.) 방식으로, 나머지는 bias는 0, weight는 평균은 0 분산은 0.01을 갖는 가우시안 분포로 랜덤하게)
- Dropout : 처음 2개의 fc layer에 대해 0.5로 적용
- Data augmentation
- Single-scale : 이미지를 256으로 resize하고 224 x 224로 crop한 input으로 train 이후 384로 resize한 이후 384로 crop한 input으로 learning rate를 0.001로 변경 후 train
- Multi-scale : 이미지마다 범위 256~512로 resize하고 224 x 224로 crop (Scale Jittering이라고도 함.)
Testing
1. Dense evaluation
GoogLenet 처럼 multi-crop 방식으로 테스트 data를 augmentation 하고 voting을 하고 추가적으로 “OverFeat_Sermanet(2014)[3]”에서 사용한 dense evaluation을 사용했다.
아래 그림은 OverFeat 논문에서 설명하는 그림이다.
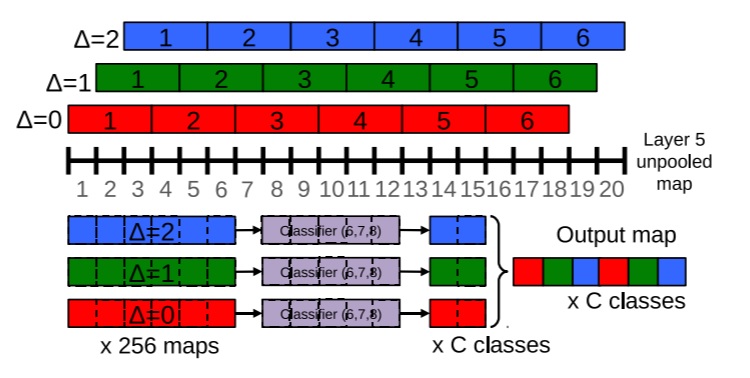
Non-overlapping maxpooling을 하게 되면 잃어버리는 정보가 생겨나는데 위의 그림처럼 1단위로 C번 x축과 y축에 offset을 줘서C개의 pooling된 이미지를 추출하고자 하는 것 이다.
2. FC layer to Conv layer
VGG는 test시에 image의 shape에 종속되지 않기 위해 Fully Connected layer를 1 X 1 크기를 갖는 Convolution layer로 취급했다. 이것 역시 Overfeat[3]에서 사용한 방식이다.
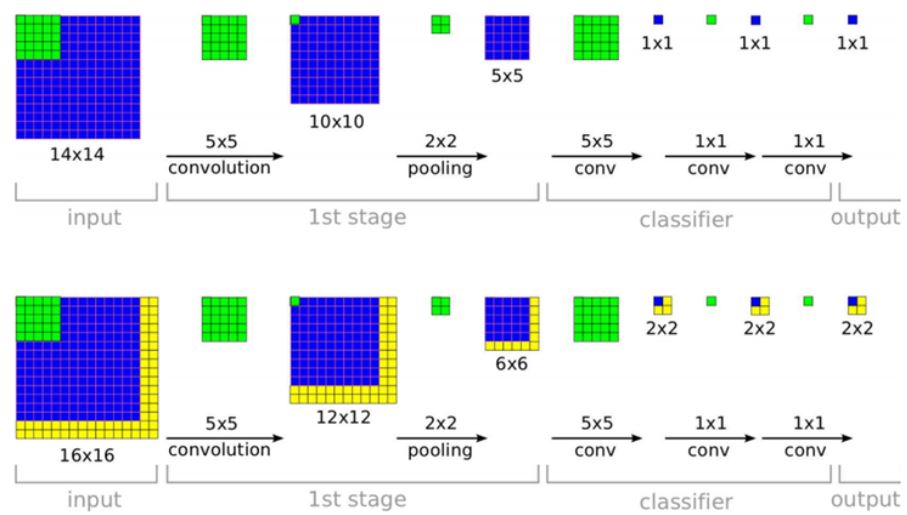
조금 더 이해가게 풀자면 train 시 마지막 Convolution layer의 output shape이 7 x 7 x 512이므로 Fc layer의 파라미터 수는 [7x7x512 크기의 1차원 weight가 4096개, 4096 크기의 1차원 weight가 4096개, 4096 크기의 1차원 weight가 1000개] 이다.
이를 Convolution으로 본다면 [7x7x512 shape filter 4096, 1x1x4096 shape filter 4096, 1x1x4096 shape filter 1000]으로 볼 수 있다.
이렇게 되면 위 사진과 같이 이미지가 기존 보다 큰 경우 2x2x1000으로 나올 수 있는데 같은 인덱스를 평균내서 1x1x1000으로 한다. 그리고 이후는 동일하다.
Evaluation
single-scale로 augmentation 한 network와 multi-scale로 augmentation한 netowrk, evaluation시 dense,multi-crop에 대한 결과는 ILSVRC-2012 dataset에서 평가했으며 마지막은 ILSVRC-2014 dataset에서 처음 제출한 결과와 나중에 dense&multi-crop을 추가한 결과이다.
1.Single scale
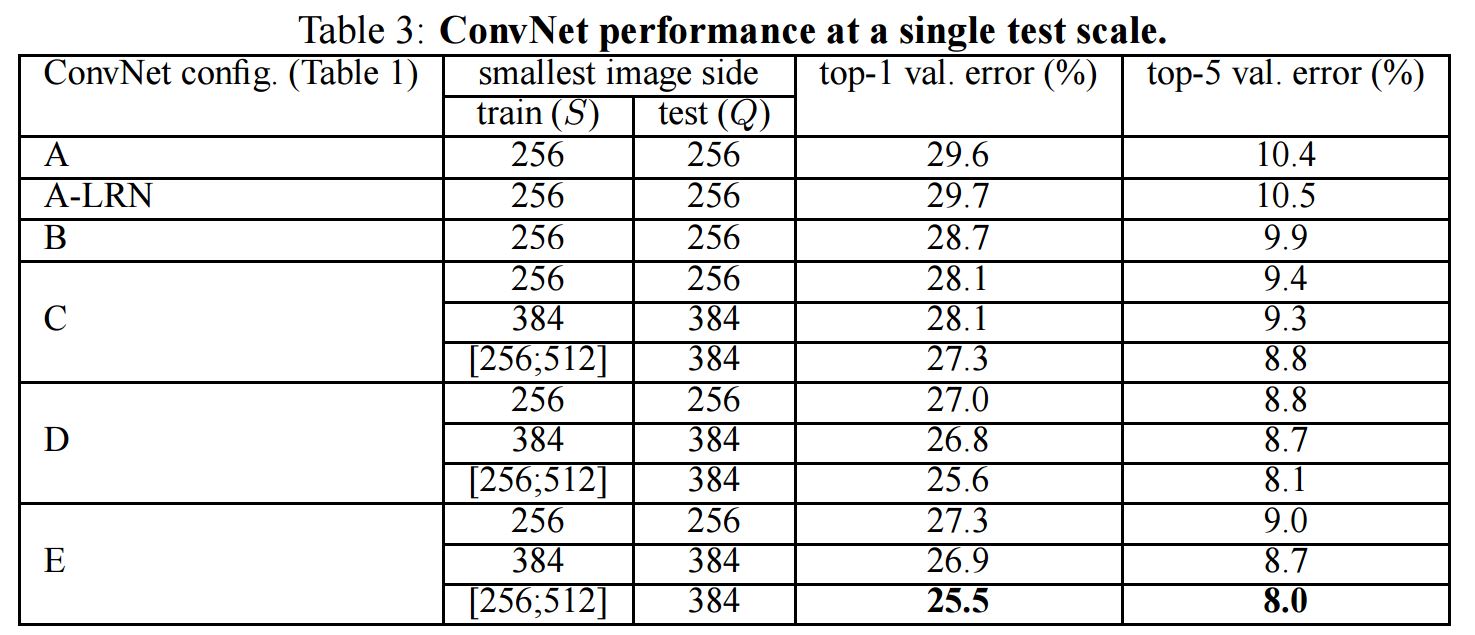
위 결과에서 B부터 왜 LRN이 빠졌는 지 알 수 있다.
2.Multi scale
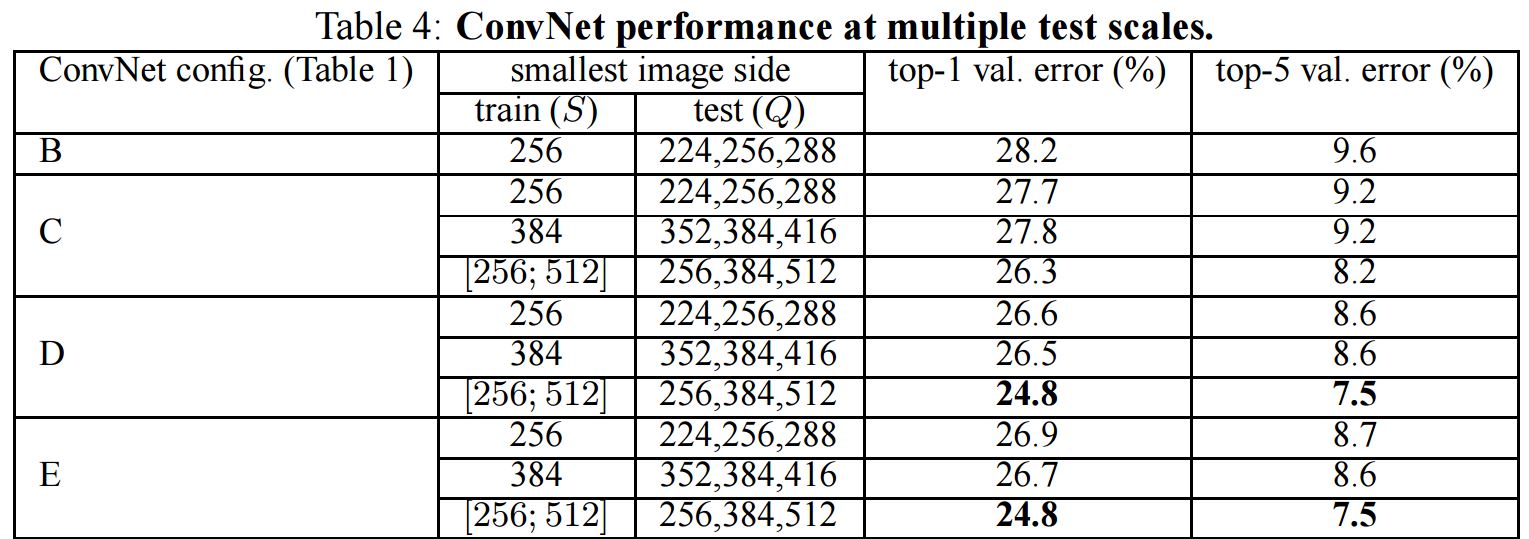
3.Dense & Multi-crop
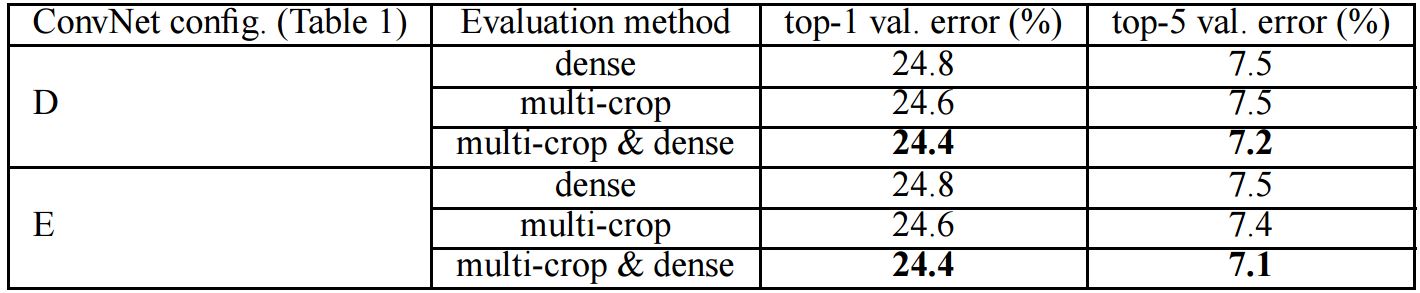
4.ILSVRC-2014
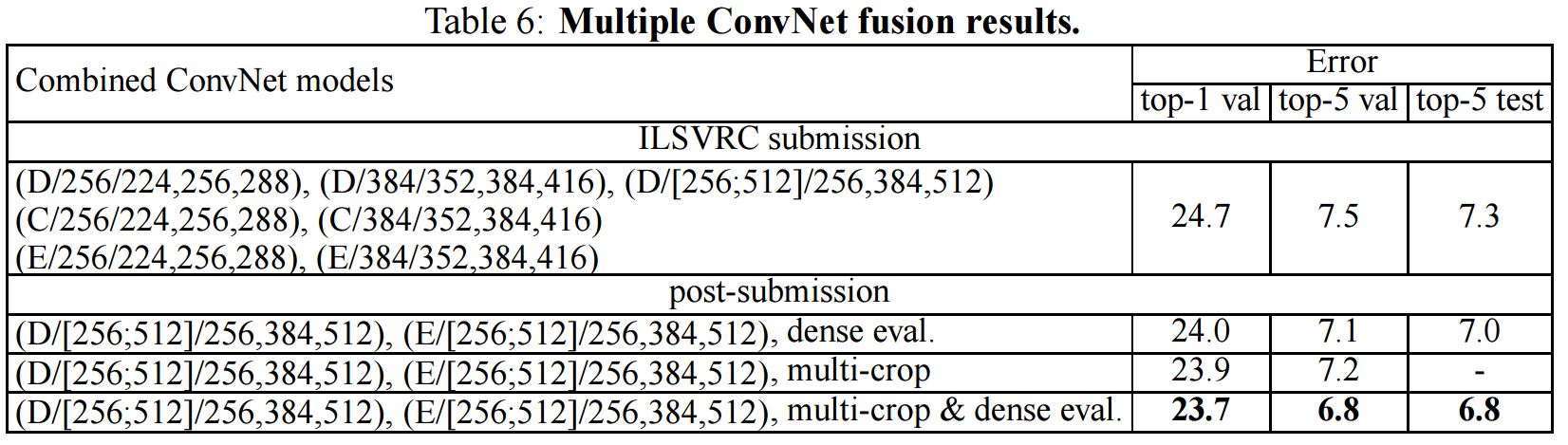
ILSVRC-2014 Classification
아래 사진은 ILSVRC-2014 dataset에서 다른 모델들과 비교한 결과이다.
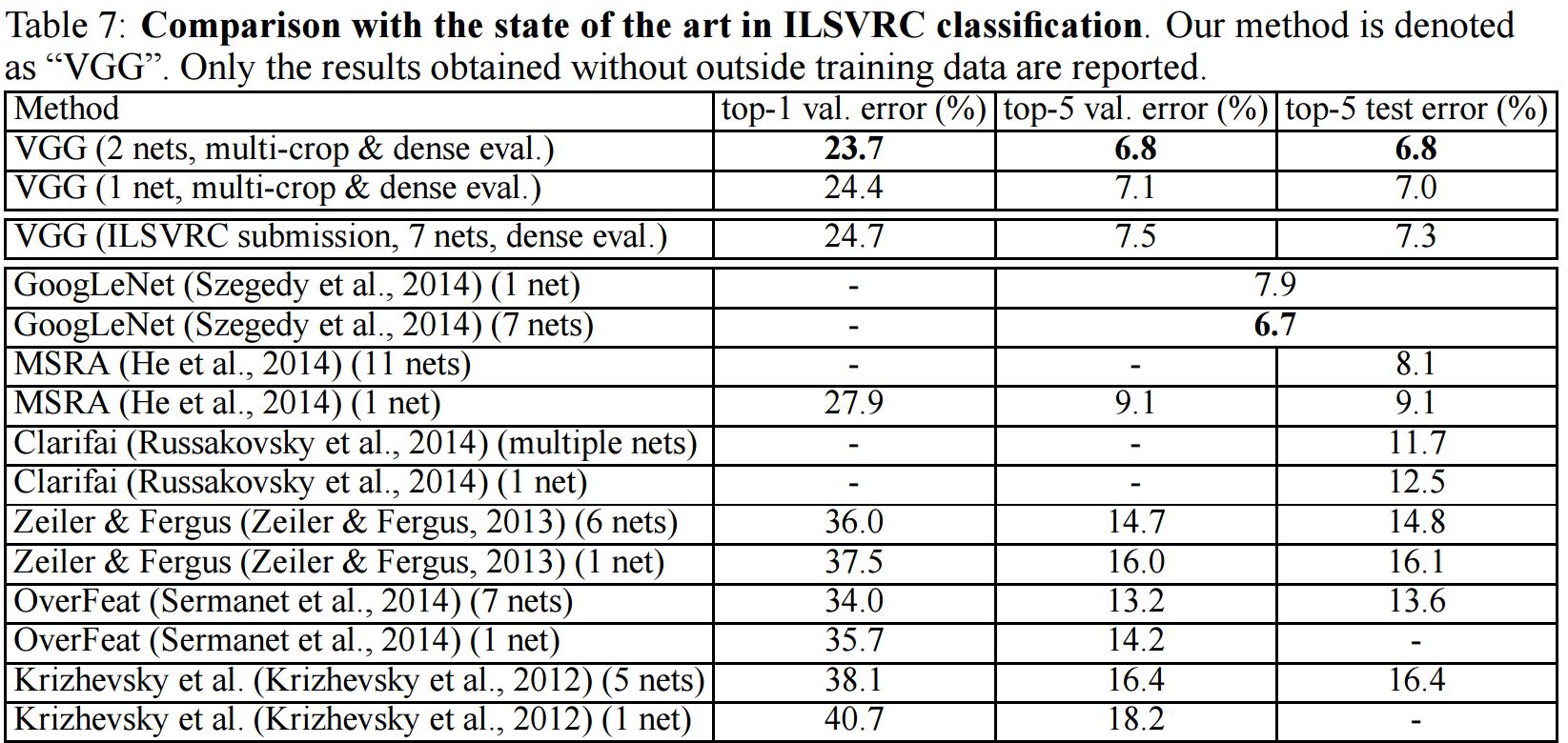
위 사진에서 비록 VGG는 2등이지만 논문에서 설명한 바와 같이 Alexnet의 구조에서 크게 벗어나진 않았다. 이러한 단순함으로 GoogLenet보다 더 많이 이용될 수 있었다.
Reference
[1] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.
[2] X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010.
[3] Sermanet, P., Eigen, D., Zhang, X., Mathieu, M., Fergus, R., and LeCun, Y. OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks. In Proc. ICLR, 2014.
Comments