Alex net은 2012년 제프리 힌튼 교수팀에서 연구되었다.
이미지넷에서 주고나하는 ILSVRC (Large Salce Visual Recognition Competition)에서 top5 test error 기준 15.4 %를 기록해 큰 폭으로 1위를 차지했다.
또한 DropOut이나 ReLU 같은 다른 논문에서 제안된 방법론들을 네트워크 설계에 차용했으며 이후 여러 논문에서도 이 두개의 논문이 많이 쓰여짐.
배경
- 이전과 달리 ImageNet, VOC 같은 대규모 dataset이 등장함.
- GPU 성능이 받쳐주기 시작함.
Architecture
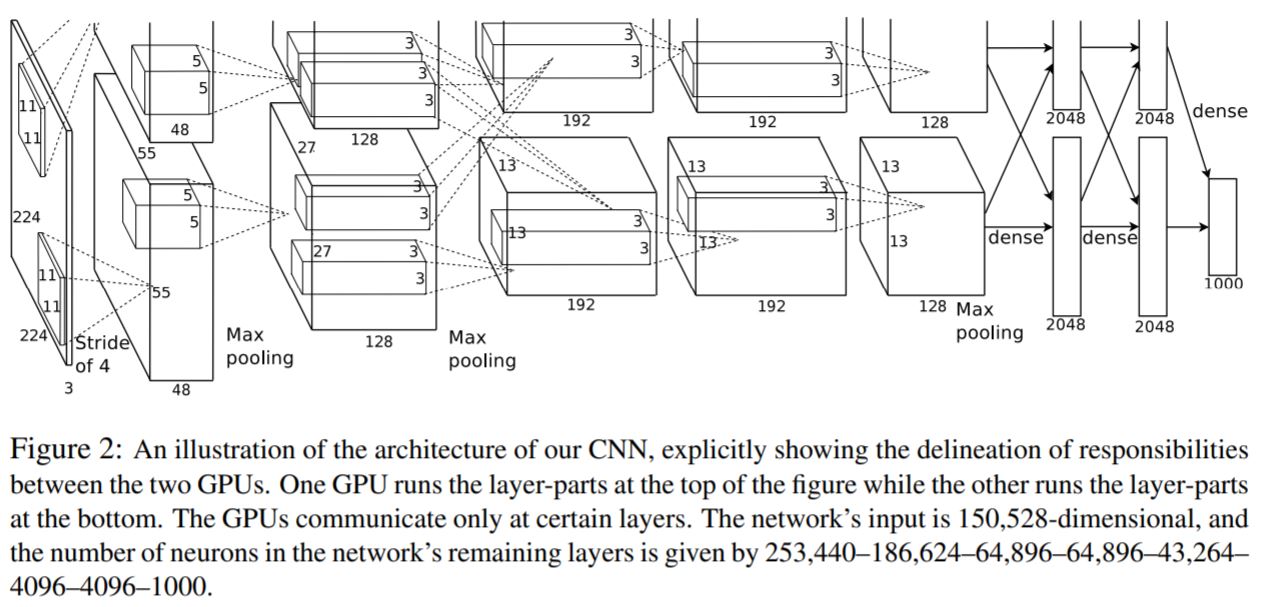
| Name | Input | Out size | Layer |
|---|---|---|---|
| Input | - | 227 x 227 x 3 | 논문에서는 224 x 224 x 3인데 이후 shape을 맞추기 위해 227로 구현하는 경우가 많다. |
| Conv1 | Input | 55 x 55 x 96 | 11x11x96, stride 4, ReLU |
| LRN1 | Conv1 | 55 x 55 x 96 | |
| Max pooling1 | LRN1 | 27 x 27 x 96 | 3x3, stride 2 |
| Conv2 | Max pooling1 | 27 x 27 x 256 | 5x5x256, stride 1, padding, ReLU |
| LRN2 | Conv2 | 27 x 27 x 256 | |
| Max pooling2 | LRN2 | 13 x 13 x 256 | 3x3, stride 2 |
| Conv3 | Max pooling2 | 13 x 13 x 384 | 3x3x384, stride 1, padding, ReLU |
| Conv4 | Conv3 | 13 x 13 x 384 | 3x3x384, stride 1, padding, ReLU |
| Conv5 | Conv4 | 13 x 13 x 256 | 3x3x256, stride 1, padding, ReLU |
| Max pooling3 | Conv5 | 6x6x256 | 3x3, stride 2 |
| FC layer1 | Flatted_Max pooling3 | 4096 | ReLU, Dropout |
| FC layer2 | FC layer1 | 4096 | ReLU, Dropout |
| FC layer3 | FC layer2 | 1000 | Softmax |
논문에서는 GPU를 병렬로 사용하였다. 2,4,5 번째 convolution layer는 같은 gpu에 존재하는 이전 layer의 kernel에만 연결 된다.
ReLU
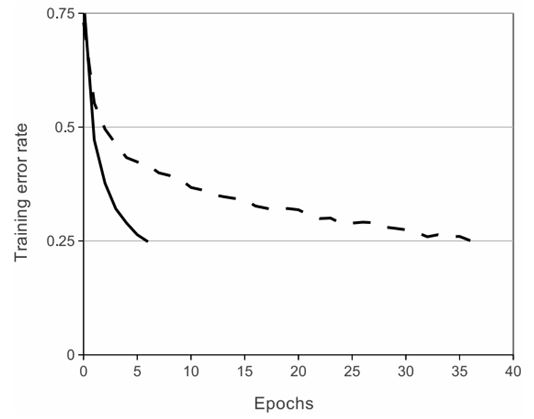
- sigmoid 함수와 hyperbolic tan(tanh)의 경우 각각의 무한대 값에 대해 (0,1) , (-1,1) 로 수렴한다. 이러한 non linearity 함수를 Saturating nonlinearity 함수라고 한다.
- Saturating linearity의 경우 포화 구간에서 gradient가 0에 수렴한다. 따라서 학습속도가 더디다.
-
Relu는 non-saturating nonlinearity 중 하나이며 2010년 nair[2]에 의해 제안된 방식이다.
- non-saturating nonlinearity를 사용하면 Saturating nonlinearity에 비해 학습속도가 빠르며 이는 많은양의 학습데이터를 훈련하는 과정에 이득을 가져온다.
- 위의 이유로 Saturating 함수를 쓰는 경우 이를 방지하기 위해 normalization 과정을 수행하는데 ReLU는 이 과정을 거칠 필요가 없다는 장점이 존재한다.
- 위 그림에서 실선이 ReLU, 점선이 Saturating이다.
Local Response Normalization
Local Response Normalization은 실제 뉴런에서 발견된 later inhibition을 구현한 것이며, 강한 자극 주변이 주변의 약한 자극들이 전달되는 것을 방해하는 효과라고 이해하면 편하다. 식은 아래와 같다.
\[b_{x,y}^{i} = \frac{a_{x,y}^{i}}{(k+\alpha \sum_{j=max(0,i-n/2)}^{min(N-1,i+n/2)}(a_{x,y}^{j})^{2})^{\beta}}\]여기서 b가 결과이며 \(a_{x,y}^{i}\)는 입력값에서 convolution연산을 거친 i번째 채널의 x,y 위치의 값, n은 인접한 kernel의 수, N은 layer에서 kernel의 총 수이다.
쉽게 생각하면 n만큼의 인접채널 중 같은 x,y 위치에 있는 값들을 함께 고려하는 것이다.
\(k,n,\alpha,\beta\)는 모두 hyper parameter이며 논문에서는 각각 \(2,5,10^{-4},0.75\)로 설정했다.
Dropout
Dropout[3]은 과적합을 막기 위한 규제 기술의 일종이다. 방식은 fully-connected layer의 뉴련 중 일부를 끄면서(w를 0으로) 진행하는 것이다.
동일한 모델을 서로 다른 초기 가중치로 train하는 방식을 앙상블(Ensemble)이라고 하는데 이와 같은 효과를 낸다.
inference시에는 모든 뉴련을 사용하며 본 논문에서는 50% 비율로 Dropout을 하였다.
Data Augmentation
Overfitting을 방지하기 위한 또 하나의 방법으로 image translations, horizontal reflection, random crop 등을 이용해 Data Augmentation을 수행했다.
또한 추가적으로 ImageNet의 training set에서 RGB 값들에 대해 PCA를 수행하고 평균 0, 표준편차 0.1 크기를 갖는 랜덤 변수를 곱하고 원래 픽셀 값에 더해주는 방식으로 컬러 채널의 값을 바꾸어 다양한 영상을 얻었다. 아래의 식에서 \(p\)와 \(\lambda\)는 각각 고유 벡터와 고유 값이다.
이 방식을 PCA Color Augmentation이라고 한다. 현재는 잘 사용하지 않는 방식이다.
Details of learning
- Optimizer : Stochastic gradient descent
- Batch size : 128
- Momentum : 0.9
- Weight decay : 0.0005
- Learning rate : 0.01, validation error rate가 줄지 않을 때마다 1/10 배
- Epoch : 약 90
Reference
[1] A. Krizhevsky, I. Sutskever, and G. Hinton. Imagenet classification with deep convolutional neural networks. In NIPS, 2012.
[2] V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th
International Conference on Machine Learning, 2010.
[3] G.E. Hinton, N. Srivastava, A. Krizhevsky, I. Sutskever, and R.R. Salakhutdinov. Improving neural networks
by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012.
Comments